��3�� �T�[�r�X�E�R���e���c�Z�p
3.1.1 �����̍��x���i4K�E8K�Ή��j
3.1.4 HDR�i�n�C�_�C�i�~�b�N�����W�j
3.1.7 22.2ch �O�����}���`�`�����l����������
3.2.4 �����O�ɂ�����IoT���c��A�W�����@�ւȂ�
3.2.5 IoT�̃r�W�l�X���Ƃ���ɂƂ��Ȃ��ۑ�
3.2.7 Federated Learning�i�A���w�K�j
��3�� �T�[�r�X�E�R���e���c�Z�p
3.1�@ �����T�[�r�X
3.1.1�@ �����̍��x���i4K�E8K�Ή��j
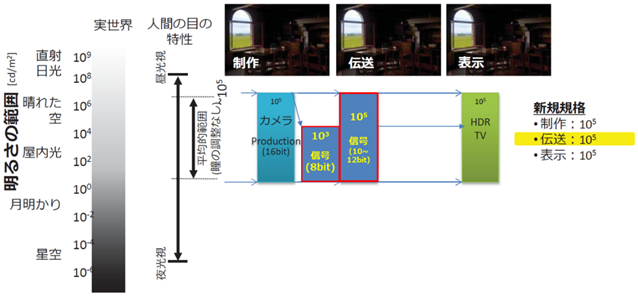
�{�͂ł́A�����̍��x���Ƃ��āA�������דx�ł���4K�E8K�t�H�[�}�b�g�A���P�x���̋Z�p�ł���HDR�iHigh Dynamic Range�j�A�ŐV�̕����E�ʐM�T�[�r�X�ɑΉ����邱�Ƃ��\�Ƃ���MMT�iMPEG Media Transport�j���d�������A�������ꂽ�X�N�����u�������ɑΉ��\��ACAS�A�܂�4K�E8K�����̂��߂̓`���Z�p�Ƃ��āA�q���f�W�^�������ƃP�[�u���f�W�^�������̗�ɂ��Đ�������B����ɁAVR�iVirtual Reality�j�f���̑�\�I�Ȍ`�Ԃł���360�xVR�f���ɂ��Ă���������B
�q���f�W�^�������ł́A���o124/128�xCS�f�W�^�������ł̓X�J�p�[JSAT��2015�N3������4K���p�������J�n���ABS�f�W�^�������ł�4K�E8K�̎���������NHK��2016�N8���ɁAA-PAB��2016�N12���ɊJ�n���A2018�N12���ɂ�4K�E8K�̎��p�������J�n���ꂽ�B����ɁA���o110�xCS�f�W�^�������ł�2017�N��4K�̎����������J�n���A2018�N��4K���p�������J�n���ꂽ�B
IP�ɂ������iIPTV�j�Ƃ��ẮANTT�Ղ�炪2015�N12������4K�̎��p�������J�n�����B
�P�[�u���e���r�ł́ARF�ɂ�鎩�������2015�N12���ɃP�[�u��4K�Ƃ��Ď��p�������J�n���AIP�ɂ��P�[�u��4K������2016�N4������J�n���Ă���B
�����Ȃ������Ă���u4K�E8K���i�̂��߂̃��[�h�}�b�v�v���} 3‑1�Ɏ����B
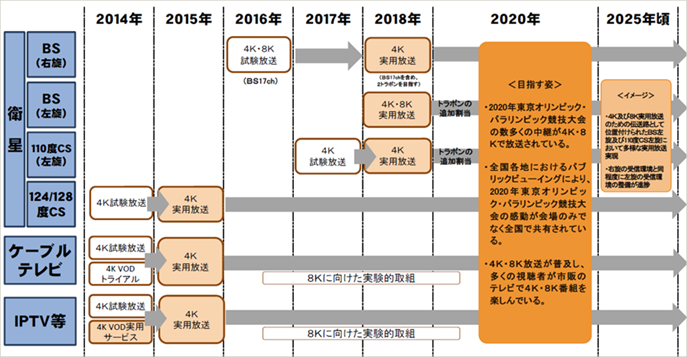
�} 3‑1�����Ȃ�4K�E8K���i�̂��߂̃��[�h�}�b�v
3.1.2�@ 4K�E8K�����̂��߂̍��x��
�{�߂ł́A4K�E8K�����̍��x���ƁA�֘A�������x���Z�p�Ƃ��āAHDR�iHigh Dynamic Range�j�AMMT�iMPEG Media Transport�j���d�������AACAS�ɂ��Đ�������B�����̋Z�p���W���鑗�M���Ǝ�M���̕������} 3‑2�Ɏ����B
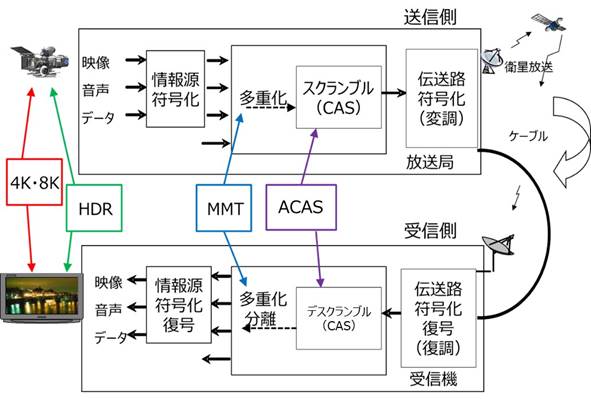
�} 3‑2�@4K�E8K�AHDR�AMMT�AACAS�̊W����
3.1.3�@ 4K�E8K�Ƃ�
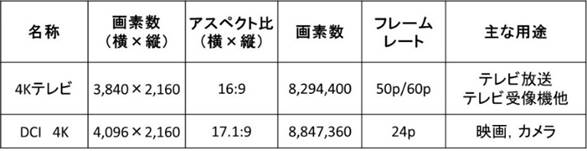
4K�E8K�͉f���t�H�[�}�b�g�̉𑜓x���Ӗ����Ă���A4K�t�H�[�}�b�g���Ƃ����\ 3‑1�Ɏ����B
�������̉�f���́AITU����߂��K�i�Ɖf�搧���Ђ̉����c��DCI�iDigital Cinema Initiatives�j����߂��K�i��2�ʂ肪����A4K�ƌĂ�鍪����4,096��4�~1,024�ł��邱�ƂɈ���i�L���������̗e�ʕ\����2��10��ł���1,024��啶����K�ŕ\�����A1,000��\����������k�ƕ\�L���\�L���Ă���j�B
���\�Ɏ���4K�e���r�̓e���r�����p�ŁADCI 4K�͉f���J�����p�ł���B��f����4K�e���r�i�A�X�y�N�g��16:9�j��3,840�ŁADCI 4K�i�A�X�y�N�g��17.1:9�j��4,096�ł���B�t���[�����[�g�͌�q���邪�A4K�e���r�͖��b50�t���[����50p�i���B�Ȃǁj�Ɩ��b60�t���[����60p�i���{�A�č��Ȃǁj��DCI 4K�͖��b24�t���[����24p�ƈقȂ��Ă���B
�\ 3‑1�@�f���t�H�[�}�b�g�̉𑜓x��i4K�j
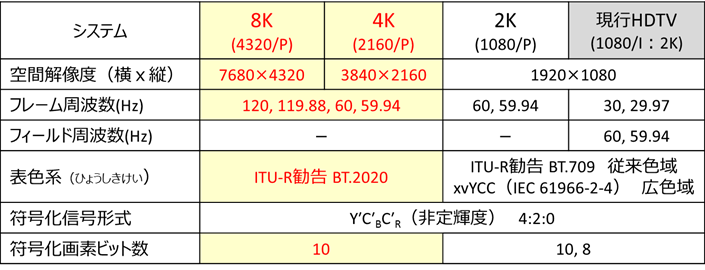
�܂��A8K�E4K�E2K�Ȃ�тɌ��sHDTV�i2K�j���r���āA�\ 3‑2���f���t�H�[�}�b�g�̉𑜓x�������B
�\ 3‑2�@�f���t�H�[�}�b�g�̉𑜓x�i8K�E4K�E2K �j
4K�E8K�Ɖ𑜓x�������Ă���Ƃ��̏��r�b�g�����}�����邽�߁A�R�[�f�b�N�Z�p�̐i�����K�v�ł���A���̊W���\ 3‑3�Ɏ����B
�\ 3‑3�@�摜���f�B�A�ƃR�[�f�b�N�Z�p�̐i���ɂ��`�����x��r��i�T���j

3.1.4�@ HDR�i�n�C�_�C�i�~�b�N�����W�j
HDR�iHigh Dynamic Range�j�́A���掿���̂��߂̋P�x�\���̊g���Z�p�ł���A�P�x�̃_�C�i�~�b�N�����W���L���邱�Ƃł���B
3.1.4.1�@ �Î~���HDR�Ɠ����HDR
HDR�͋P�x�̃_�C�i�~�b�N�����W���L�����邱�Ƃ��w�����A�Î~��Ɠ���ł͂��̎�@���قȂ��Ă���B�Î~��i�ʐ^�j�̕��̐��E�ł̓X�}�[�g�t�H���̃J�����ɂ�HDR�@�\�����ڂ����ȂNJ��ɕ��y���i��ł���BHDR�ʐ^�Ƃ́A�} 3‑3�Ɏ����悤�ɃJ�����̃_�C�i�~�b�N�����W�̋�����₤���߂ɃV���b�^�[�X�s�[�h��ς��ĈقȂ�I�o�ŘA�����ĕ������̎ʐ^���B�e���A�ꖇ�̉摜�ɍ������邱�Ƃɂ���ĉ摜�̎��_�C�i�~�b�N�����W�̕����ő���Ɉ����o�����Ƃ������̂ŁA�����E�̉摜�����̂܂܋L�^������̂ł͂Ȃ��A�l�H�I�ȉ摜�����Z�p�̈�ł���B

�} 3‑3�@�I�����Ԃ̈قȂ�摜����������HDR�ʐ^�̗�
�i�o�T�F https://www.digitaltrends.com/photography/what-is-hdr-photography/�j
����ɑ��āA�e���r������l�b�g�z�M�A���f�B�X�N�ɂ��p�b�P�[�W���f�B�A�ł̉掿���P�Ƃ��Ęb��ƂȂ��Ă��铮���HDR�Ƃ́A�f������荞�ގB���Z���T�������Ă���L���_�C�i�~�b�N�����W�̐M�������̂܂ܗʎq���i�f�W�^�����j���ċL�^���A���̐M�����e���r���Ńf�B�X�v���C�̋P�x���\�ɍ��킹�āA�g�����ꂽ�_�C�i�~�b�N�����W�̉f���M���𒉎��ɍĐ��\�����悤�Ƃ���Z�p�ł���A�ʐ^�ł���HDR�Ƃ͍l�������قȂ�B
���R�E�̋P�x�����W�́A�} 3‑4�Ɏ����悤�ɁA���̏o�Ă��Ȃ����̐��Ƃ炷�n�ʂ̖��邳��100������1nit�icd/m2�j���x�ŁA���z�̒��ڌ���10��nit�ƌ����Ă���A�c��ȕ��������Ă���B
�l�Ԃ̖ڂ����ɗD�ꂽ���o�����������Ă���A100������1nit����1��nit���x�܂Ŏ��F�ł��A����10��14��i140dB�j�߂��_�C�i�~�b�N�����W�������Ă��邪�ACRT����Ƃ���RT.709�̃_�C�i�~�b�N�����W�͂��܂�ɂ������A�����̏�����Ă����B�ߔN�̉t���e���r�́ACRT�ɔ�ׂăs�[�N�P�x��R���g���X�g�ɉ����Ċi�i�̐i���𐋂��Ă��邽�߁A�����̐��\���\�������o���āA�]���摜�̔���I���P���������錟��������Ă����B
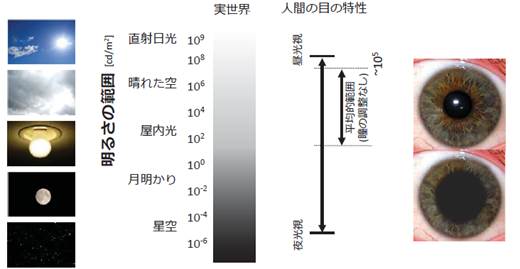
�} 3‑4�@���R�E�̋P�x vs �l�Ԃ̎��o�\�͈�
�i�o�T�F�����ȕ����V�X�e���ψ���HDR��Ɣǎ����@HDR��1�|3�uHDR�Z�p�Ɋւ��铮���v�j
�} 3‑5��HDR���܂ލ��掿���̂��߂̋Z�p�������B
CRT�̃e���r�ł͍��P�x�̂��̂ł���������200nit���x�ł������̂ɑ��A�t���e���r�͕W���̂��̂ł�400nit���x�̃s�[�N�P�x������A�����^LED�o�b�N���C�g�V�X�e���̂��̂ł����1,000nit����s�[�N�P�x��������̂ŁA�����K�i�ōČ��ł��Ȃ��������P�x�����̊K�������R�E�ɋ߂��P���Ńe���r��ʏ�ɕ\������̂�HDR�ł���B
�} 3‑5�@HDR�ȂǍ��掿���̂��߂̋Z�p
�i�o�T�F�����ȕ����V�X�e���ψ���HDR��Ɣǎ����@HDR��1�|3�uHDR�Z�p�Ɋւ��铮���v��JLabs�C���j
3.1.4.2�@ HDR�̌���
4K�E8K����̓`���ɍۂ��āAHDR�Ɗ����̕����ł���SDR�Ƃ��r���A�} 3‑6�����掿���̂��߂�HDR����舵�����邳�͈̔͂������B
�} 3‑6�@���掿���̂��߂�HDR����舵�����邳�͈̔�
�i�o�T�F�����ȕ����V�X�e���ψ���HDR��Ɣǎ����@HDR��1�|3�uHDR�Z�p�Ɋւ��铮���v�j
HDR�ł̓J�����ŎB�e���ꂽ105�̋P�x�͈͂�`���H�ł�105�̋P�x�͈͂��ێ����AHDR�Ή��e���r��105�̋P�x�͈͂��Č�����B
���s��SDR�ł̓e���r�̃s�[�N�P�x��100 nit���W���ł��������߁A��������103���x�����`�����Ă��Ȃ������B
HDR�M����SDR�M���i����̓`���j�̔�r���} 3‑7�Ɏ����B���̊O�������SDR�ł͖��邢�Ƃ��낪�\���ł��Ă��Ȃ����Ƃ��킩��B
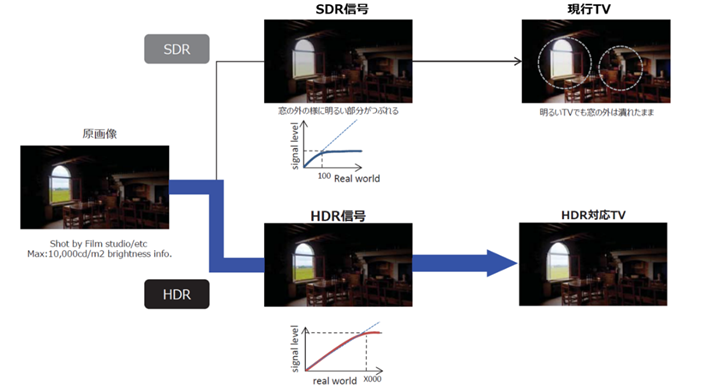
�} 3‑7�@HDR�ɂȂ����ۂ̉摜��
�i�o�T�F�����ȕ����V�X�e���ψ���HDR��Ɣǎ����@HDR��1�|3�uHDR�Z�p�Ɋւ��铮���v�j
3.1.4.3�@ ITU-R�ɂ�����HDR�W��������
ITU-R WP6C�i�ԑg���삨��ѕi���]���jSWG6C-4�i�f���jSWG4�@DG-1�i�n�C�_�C�i�~�b�N�����W�e���r�j��HDR��R�c���Ă���A������EIDRTV�iExtended Image Dynamic Range TV: �f���_�C�i�~�b�N�����W�g���e���r�j�ƌĂ�ł����B
2016�N7���A�č���PQ�iPerceptual Quantization�j�����Ɠ��{�^�p���Ăł���HLG�iHybrid Log-Gamma�j������2�������L�ڂ����V�����āuBT.2100�v�i�ԑg����ƍ��۔ԑg���ʂŎg�p����HDR�e���r�̉f���p�����[�^�l�j��ITU-R�����F���ꂽ�B�������̔�r���\ 3‑4�Ɏ����B
�\ 3‑4�@HDR�����̔�r
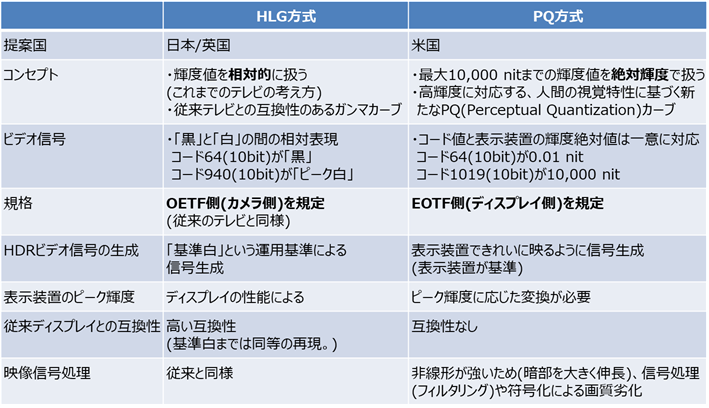
�@ �n�C�u���b�h�@���O-�K���}�iHLG�j����
�n�C�u���b�h�@���O-�K���}�iHLG�j�����́A�Õ��ɏ]���̃K���}�J�[�u�A�����Ƀ��O�J�[�u���̗p����n�C�u���b�h�����ŁA�u����v�Ƃ̑��Βl�ɂ��ϊ������g�p���邽�ߏ]���̃e���r�Ƃ̌݊����������̂������ł���B
�J�������Ō��̋P�x��d�C�M���ɕϊ������-�d�C�`�B���iOETF�FOpto-Electronic Transfer Function�j���K�肵�Ă���A�J�������̃t�B���^�̂悤�ɗp���邽�߁A�����̂悤�ɐ��̉f����͂��Ȃ���Ȃ�Ȃ��ꍇ�ɓK���Ă���B�t�ɁA�f�B�X�v���C�����d�C�M�������̋P�x�ɕϊ���������́A�d�C-���`�B���iEOTF�FElectro-Optical Transfer Function�j�ƌĂԁB
�{�����́A���^�f�[�^�𗘗p�����ɈقȂ�P�x�̉�ʊԂ�قȂ郁�[�J�̑��݉^�p����S�ۂ���B
HLG������OETF��EOTF�̃J�[�u���} 3‑8�Ɏ����B
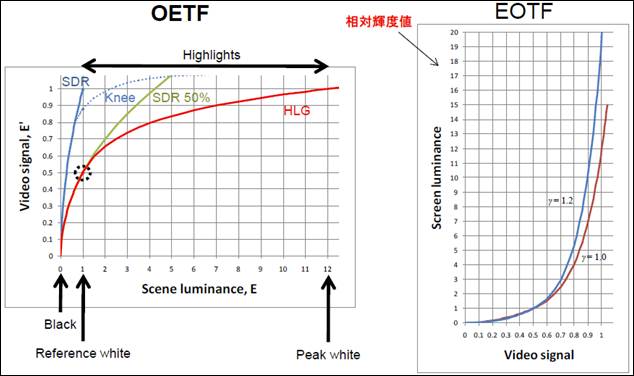
�} 3‑8�@OETF/EOTF�iHLG�j
�i�o�T�F�����ȕ����V�X�e���ψ���HDR��Ɣǎ���
HDR��2-3�ʎ��uHDR���������̒�āv���������j
�A PQ����
�ő�10,000nit�܂ł̋P�x�l���P�x�ň����A�l�Ԃ̎��o�����Ɋ�Â��V���ȃK���}�J�[�u�iPQ�FPerceptual Quantization�j���̗p����BPQ�J�[�u���} 3‑9�Ɏ����B
�d�C�M�����C�R���C�W���O����O���[�f�B���O��Ƃŗ\�ߌ��߂�ꂽ��Βl�ɂ����́^�o�͂̊W�����g�p���邽�߁A����Ɏ��ԂƃR�X�g���|������f��Ȃǂ̍�i�������R���e���c�ɓK���Ă���B

�} 3‑9�@EOTF�iPQ�j
�i�o�T�F�����ȕ����V�X�e���ψ���
HDR��Ɣǎ���HDR��2-3�ʎ��uHDR���������̒�āv�j
3.1.4.4�@ ������HDR�K�i������
���{�����ŕ��������Ƃ���HDR�������K�i�����邽�߂ɂ͑����Ȃ̏ȗߍ������Ȃĕ����@�����肷��K�v�����������AARIB�i��ʎВc�@�l�d�g�Y�Ɖ��j�ł�2015�N7����ARIB STD-B67 1.0�Łu�gEssential Parameter Values for the Extended Image Dynamic Range Television (EIDRTV) System�v�����肵���B
���̌�AHDR��K�p����f���̋�ԓ����Ǝ��ԓ������܂߂����ۓI�ȍ��ӂ������A����ITU-R BT.2100��2017�N6���ɉ������ꂽ���Ƃ��A2018�N1����2.0�ł����肵�A�K�i�����uParameter Values for the Hybrid Log-Gamma(HLG) High Dynamic Range Television (HDR-TV) System�v�ɕύX�����B
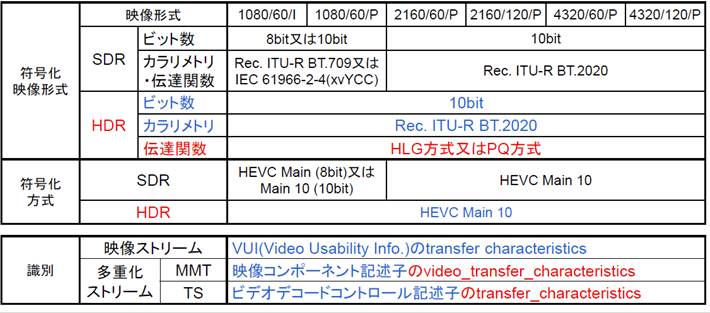
ITU-R�̊��������ISO/IEC JTC 1/SC 29/WG 11 �iMPEG�j�̕W���K�i����Q�Ƃ���邱�Ƃ�z�肷�邽���A�p���ł����{�ƂȂ��Ă���B���e��HLG�������߂����̂ŁA�ȉ���4���ڂɂ��ċK�肵�Ă���B
(1) OETF�ɂ�����V�X�e���p�����[�^���K��i���o���̋K��j
(1) ���F�p�����[�^ (���F�A����F�̍��W�j�FITU-R BT.2020���̗p
(2) �M���t�H�[�}�b�g�i����`���j�FGamma�{Log�̃n�C�u���b�h����
(3) �f�W�^���l�F����Peak�l�A������x���l�A���i0%�j���x���l���̃f�W�^���l�i10bit/12bit�j���K��
HDR���������S�ʂɂ��ẮA���ʐM�R�c�� ���ʐM�Z�p���ȉ� �����V�X�e���ψ���HDR��Ɣǂ��A2016�N3����HLG��PQ�o���ւ̑Ή���A���d���X�g���[���ɂ�����`�B���̎��ʓ��ɂ��ĕ��ɂ܂Ƃ߂Ă���B���̊T�v���\ 3‑5�Ɏ����B
�\ 3‑5�@HDR���������̊T�v
3.1.4.5�@ �u���[���C�f�B�X�N�ɂ�����HDR�K�i������
�������4K�ɑΉ������u���[���C�̋K�i�Ƃ��ĕW�����c��BDA�iBlu-ray Disc Association�j���uUltra HD Blu‒Ray�v�K�i�𐧒肵���B�} 3‑10�Ɏ����悤�ɁA���̒��ɂ�HDR���W���d�l�Ƃ��ċK�肳��Ă���AEOTF�Ƃ���SMPTE�iSociety of Motion Picture and Television Engineers�F�č��f��e���r�Z�p�ҋ���j���K�i������ITU-R�ɕč��ĂƂ��Ē�Ă��Ă���ST2084�iPQ�j���̗p�����B�܂��ASMPTE�͍��P�x�A�L�F��̃��^�f�[�^�K�iST2086���K�肵�Ă���A������ɂ��Ă��̗p���ꂽ�B���̂��߁ABD�v���C���[��HDR�Ή��e���r���̔�����CTA�iConsumer Technology Association�j�́AHDR�̂��߂�ST2086���^�f�[�^��K�p�����C���^�t�F�[�X�d�lCTA-861.3�i���^�f�[�^�g���K�i�j�𐧒肵���B
����ɑ��AHDMI�t�H�[������HDMI�C���^�t�F�[�X�́ACTA���C���^�t�F�[�X�d�l���Q�Ƃ��Ă���K�i�̂��߁A2.0�ł�2.0a�łɉ��肵��CTA-861.3�ւ̑Ή����s�����B
SMPTE ST2084��EOTF�́A���Ƃ��ƃh���r�[�Ђ�HDR���������邽�߂̕\�����u�ŁA�l�Ԃ̎��o�����ɍ��킹���f�����Č����邱�Ƃ��R���Z�v�g�ɒ������̂ł��邪�A�h���r�[�Ђ̓h���r�[�r�W�����Ƃ������W�ŁA���R�E�ɋ߂��f�������P�x�f�B�X�v���C��ōČ����邽�߂Ƀ��^�f�[�^���܂�12�r�b�g���f���A�����C���[�ő��o����V�X�e�����J�����Ă���AUHD BD�̃I�v�V�����Ƃ��č̗p����Ă���B

�} 3‑10�@Ultra HD Blu-ray
3.1.4.6�@ �P�[�u���ƊE�ւ̉e��
HDR��4K�̎��ɗ��閣�͓I�ȍ��掿���̋Z�p�ł���A����ɍL�F��iITU-R BT.2020�j�̗v�f���g�ݍ��킳�邱�Ƃɂ��A�啝�ɉf���\���̉\�����L����A���܂��܂ȓW�������J�������̃C�x���g�ł����̉掿���P�̌��ʂ��F�߂��Ă���B
2018�N12��1���ɊJ�n���ꂽ�V4K�E8K�q�������ɂ�HLG�������̗p����Ă��邱�Ƃ���A���������ĕ���������{�P�[�u�����{�u���xBS�f�W�^�������@�g�����X���W�����[�V�����^�p�d�l�v�iSPEC-033/034�j�ł́ASTB��HLG�����ւ̑Ή���K�{�Ƃ��A�܂�4K����������s���u���x�P�[�u����������v�iSPEC-035�j�ł�HLG�ւ̑Ή���K�{�Ƃ��Ă���B
HDR�̉^�p�ɂ����ďd�v�Ȃ̂́A�V����TV/STB�����݂�������ł̃n�C�_�C�i�~�b�N�����W�iHDR�j�Ə]�������iSDR�j�̎��ʂƁA�ؑւ��ł���B���̂����A�f���X�g���[���̓`�B���̎��ʂɂ��ẮAVUI�iVideo Usability Information�j��transfer characteristics���h18�h�Ƃ��邱�Ƃ�HLG�����ʂ���BVUI�́AMPEG-2 TS�ł̓r�f�I�f�R�[�h�R���g���[���L�q�q�iARIB STD-B10�j�Ɋ܂܂�AMMT�ł͉f���R���|�[�l���g�L�q�q�iARIB STD-B60�j�Ɋ܂܂��B
����AHLG�iHDR�j�f������M����STB�́A�ڑ�����Ă���TV�i�e���r���j�^�[�j��HDR�Ή����ۂ����ʂ���K�v������BSTB��TV�Ԃ�HDMI 2.0b�Őڑ�����Ă���ꍇ�́AHDR�iHLG�j�Ή����ۂ���ł���BTV��HDR�iHLG�j�Ή��̏ꍇ�́AHDR�̂܂܉f�����o�͂��A�����łȂ��ꍇ�̓���͓��{�P�[�u�����{�^�p�d�l�ł͏��i���Ƃ��Ă��邪�A�ŐV��STB�ł�HDR��SDR�ɕύX���ďo�͂��邱�Ƃ����҂����B
�} 3‑11�Ɏ�M�ɂ������STB��TV�̓���������B�܂��A�} 3‑12�ɂ͔ԑg���삩���M�܂ł̐M�������Ɗ֘A����@��������B
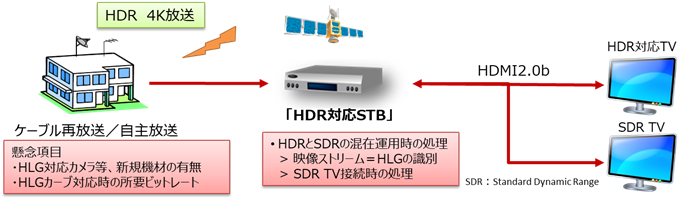
�} 3‑11�@HDR�Ή�STB�̓���
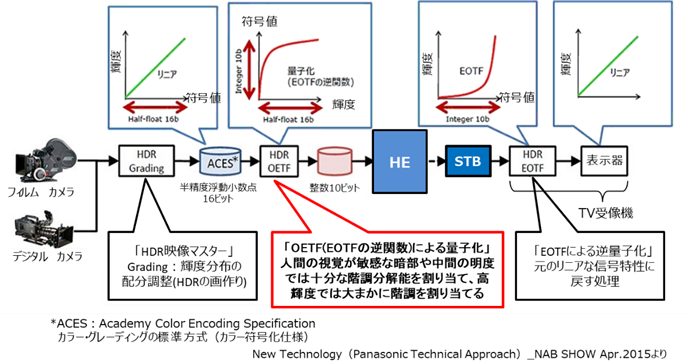
�} 3‑12�@HDR�Ή���STB��TV�Ȃǎ��Ӌ@��
3.1.4.5�@���ɂ����āACTA�K�i��HDMI�K�i�ɂ�����HDR�iPQ�����j�ւ̑Ή����q�ׂ����A�ŐV�̗��K�i�́A�ȉ��ɂ��HLG�����ɂ��Ή����Ă���B
ž 2016�N11���FCTA-861-G�u�k�����f�W�^���C���^�t�F�[�X�pDTV�v���t�@�C���v������B�O�ł�CTA-861-F��CTA-861.3�Ŋg������PQ������HDR�iHDR10�����j���T�|�[�g���Ă������ACTA-861-G��HLG�����̃T�|�[�g��lj�
ž 2016�N12���FHDMI 2.0b������B2.0b�͍ŐV�łł��������ACTA-861-G�ɑΉ�����HLG������HDR���T�|�[�g���邽�߂�HLG�`�B���̃V�O�i�����O��lj��i�Ŕԍ�2.0b�͕ύX�����j
ž 2017�N11���FHDMI 2.1�K�i���������[�X
- �ш敝�g��F18Gbps�iHDMI2.0�n�j��48Gbps
- 10K�𑜓x�܂őΉ�
- ���t���[�����[�g4K p100/120�A 8K p100/120�A10K p100/120���T�|�[�g
- �P�[�u���͐V�K�i��������݊���������A�R�l�N�^�͏]���ǂ���
- PQ�AHLG�̃V�O�i�����O�ɉ�����SMPTE ST2094�̓��I���^�f�[�^���T�|�[�g���A���I���^�f�[�^���g���ăV�[��/�t���[�����ƂɐF�[�x��f�B�e�[���A���邳�A�R���g���X�g�A�F����œK������_�C�i�~�b�NHDR������
3.1.5�@ MMT���d������
�} 3‑13�A�} 3‑14�ɐV4K8K�q�������ɗ��p�����MMT�iMPEG Media Transport�j���̑��d�������������BMMT-TLV�iType Length Value�j��������{�Ƃ��A���s��MPEG-2 TS�����ɂ��Ă��K�肪�lj�����A�^�p���邱�Ƃ��\�ł���B

�i�V�K�FNTP�EMMT�EMMT-SI�A�����K��F�f�[�^�`���EUDP/IP�ETLV�j
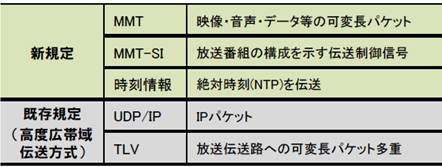
�} 3‑13�@MMT�ETLV���d������
�i�o�T�F������ �������דx�e���r�W���������V�X�e���T�v�j
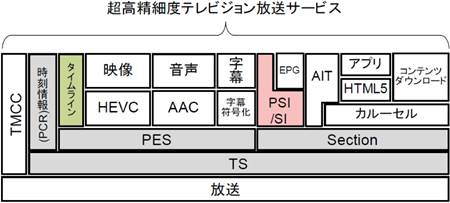
�i�V�K�ɋK�肷�镔���F�^�C�����C���A�K�i���C�����镔���FPSI/SI�A
���łɋK�肳��Ă��镔���FPCR�EPES�ESection�ETS�j
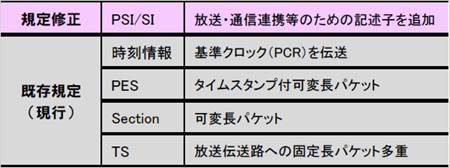
�} 3‑14�@MPEG-2 TS����
�i�o�T�F������ �������דx�e���r�W���������V�X�e�� �T�v�j
���s�̃f�W�^�������V�X�e�����J�����ꂽ�����ɔ�ׁA��������芪���R���e���c�z�M�̊����傫���ω������B�u���E�U�Ō��邱�Ƃ̂ł���}���`���f�B�A�R���e���c���������A�f���t�H�[�}�b�g�A�R���e���c�𗘗p����[���A�`���H�����l�����Ă��Ă���B������MPEG�ł́A����������V�X�e���ł̃T�[�r�X���\�Ƃ���A���܂��܂ȃl�b�g���[�N�ł̃��f�B�A�`���ɑΉ�����V�����`���K�i�Ƃ���MMT�̌������i�߂��A High Efficiency Video Coding �iHEVC�j��3D Audio��g�ݍ��킹���V���ȕW���K�i�ł���MPEG-H�V�X�e���̈ꕔ���iMPEG-H�@Part1�APart10�APart11�APart12�j�ƂȂ�A�W�������ꂽ�B
4K/8K�̎��p�����ɂ�����^�p�d�l�́AARIB TR-B39���x�L�ш�q���f�W�^�������^�p�K�� 1.2�ł����肳��A���d�������̋Z�p�W���Ƃ��Ă�ARIB STD-B60 �f�W�^�������ɂ�����MMT�ɂ�郁�f�B�A�g�����X�|�[�g���� 1.8�ł����肳��Ă���B
�܂��A�P�[�u���e���r�ł́AMPEG-2 TS�ɑ���V���d������MMT�𗘗p������3����STB�����̍��xBS�ĕ����̉^�p�d�l�Ƃ��āAJLabs SPEC-033 ���xBS�f�W�^�������g�����X���W�����[�V�����^�p�d�l�i�P��QAM�ϒ������j��JLabs SPEC-034 ���xBS�f�W�^�������g�����X���W�����[�V�����^�p�d�l�i����QAM�ϒ������j�����肵�Ă���B
3.1.5.1�@ MPEG-2 TS�̌��E��MMT
MPEG-2 TS�́A����M����N���b�N���܂߂Ċe�R���|�[�l���g��1�̃X�g���[���Ƃ��Ĉ������߁A�P��̓`���H�ɂ������̎d�g�݂�z�肵�������ł���B���������݂ł͑��l�ȃR���e���c�����݂��A�܂�����𗘗p����[�������l�����Ă���A�����ƒʐM�Ƃ̘A�g�ɂ��R���e���c�z�M�ȂǁA�����̍����T�[�r�X�����҂����悤�ɂȂ��Ă����B���̂悤�Ȋ��ω��ɑ��AMPEG-2 TS�ōŐV�̕����E�ʐM�T�[�r�X�ɑΉ�����ɂ͈ȉ��̓_�Ő�����B
ž �X�g���[�����ő��d�����������A���̃X�g���[���Ƃ̑��d�����ł��Ȃ��i��F�����X�g���[���ƒʐM�X�g���[���𑽏d�j
ž �قȂ�X�g���[���ԂŎ����������ł��Ȃ��i��F�����ƒʐM�̎��������j
ž �p�P�b�g�����Œ�i188�o�C�g�j�ŁA��e�ʃR���e���c�̓`���ł͔����
ž ��e�ʃt�@�C���̓`��������
MPEG-2 TS�ŏ�L�̐���ɑΉ�����ɂ͌��E�����邽�߁A�V���Ɏ���������V�X�e���ŗ��p�\�ȃ��f�B�A�g�����X�|�[�g�����Ƃ��Ĉȉ��̂悤�ȑΉ���}��AIP�`�����l������MMT���W�������ꂽ�B
ž �قȂ�X�g���[���𑩂˂邽�߂̃��^�f�[�^���K��
ž �قȂ�`���}�̂��o�R�����X�g���[���Ԃ̎����������\
ž �ϒ��p�P�b�g�𗘗p���A��e�ʃR���e���c�iUHDTV�Ȃǁj�̓`����������
ž �t�@�C���`����������
3.1.5.2�@ MMT�̓���
MMT�̋@�\�̓����́A�ʐM�����̎Q�Ɛ���w�肵�āA�T�[�o����擾�����ԑg�֘A���Ȃǂ��ɕ\������Ƃ��������ƒʐM�̘A�g�ɂ��n�C�u���b�h�z�M�ł��邱�Ƃł���A���̃C���[�W���} 3‑15�Ɏ����B
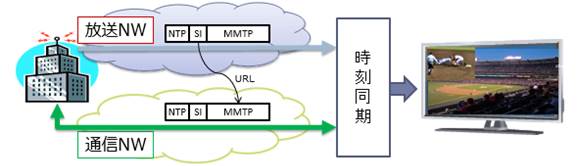
�} 3‑15�@�X�|�[�c���p�ɂ����Ď�f��������g�œ`�����A
�A���O���̈قȂ�f�����ʐM�œ`������ꍇ�̃C���[�W
�n�C�u���b�h�z�M�̎�ȋ@�\�v�f�Ƃ��āA�ȉ��̓��e����������B
ž �`���H���V�[�����X�ɐ�ւ���@�\��L���A���Ƃ��đ��M���ł͑����_�f�����̓`���H�Ŕz�M���l������B�܂���M���ł́A���Ƃ��Ήq�������ł̍~�J�����Ȃǂ̍ۂɂ͒ʐM�Ŕz�M����������M���邱�ƂŁA�p���������\�Ƃ���T�[�r�X�����B���邢�͊K�w�iScalable�j�������ɑΉ������X�g���[����z�M���邱�Ƃɂ��A�x�[�X���C��������œ`�����A�g�����C����ʐM�œ`������T�[�r�X�Ȃǂ��l�����A���̈����} 3‑16�Ɏ����B
ž ����������NTP�iNetwork Time Protocol�j�𗘗p���邱�ƂŁA�]����MPEG-2 TS���d�������ł͍�����������^�ʐM�R���e���c�Ԃ̐�Ύ����������������A�قȂ�`���H���o�R�����X�g���[���Ԃ̓������\�ɂȂ�B�܂����萢�E��UTC�iCoordinated Universal Time�j�`���œ��ꂳ�ꂽ�v���[���e�[�V�����^�C���X�^���v�iPresentation Time Stamp�j���f���≹���Ȃǂ̃R���|�[�l���g�i�A�Z�b�g�j�ɕt�^����邱�Ƃɂ��A�����x�ɓ��������T�[�r�X���ł���B
ž �A�Z�b�g���ƂɁA�����M�[���ɍ��킹�Ă��̉�ʏ�ł̕\���̈���w�肷�邱�Ƃ��ł���B
�} 3‑16�@MMT�ɂ��K�w�`���̗�
3.1.5.3�@ MMT�̍\��
���s�̕����V�X�e���ł͑��d�������i���f�B�A�g�����X�|�[�g�����j�Ƃ���MPEG�ŕW�������ꂽMPEG-2 TS�������p�����Ă���BMPEG-2 TS�ł͒P��̓`���H�ɂ�������z�肵�A����M����N���b�N���܂߂Ċe�R���|�[�l���g����̃X�g���[���Ƃ��Ĉ����Ă��邪�A���l�ȓ`���H��e���r�݂̂Ȃ炸�^�u���b�g��X�}�z���̃f�o�C�X�����݂�������ō��x�ȃT�[�r�X�����ɂ͌��E������B
���̂悤�ȍ��݊����ɂ����郁�f�B�A�z�M�ɗp�������A�̋K�i�Ƃ���2014�N3���ɍ��ەW�������ꂽ�̂��AISO/IEC 23008 MPEG-H�iHigh efficiency coding and media delivery in heterogeneous environments�j�ł���AMMT�͂���Part 1�ƂȂ��Ă���B
���Ȃ݂ɁAPart 2��4K/8K�̉f���������ɗp������HEVC�iH.265�j�ł���A����3D Audio�iPart 3�j�AForward Error Correcting Codes for MMT�iPart 10�j�AComposition coding for MMT�iPart 11�j�����K�肳��Ă���B
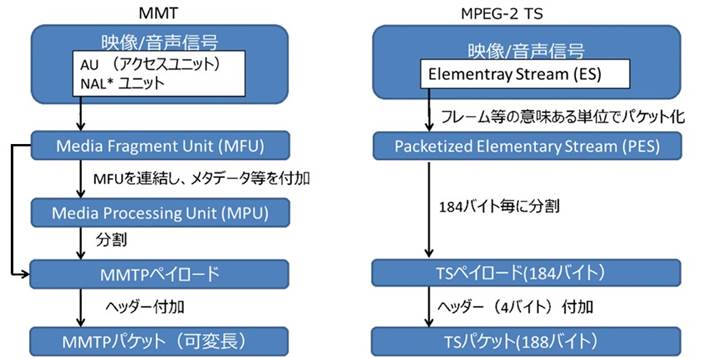
MMT�ɂ����镄�����M���̍\����MPEG-2 TS�Ɣ�r�����} 3‑17�Ɏ����B
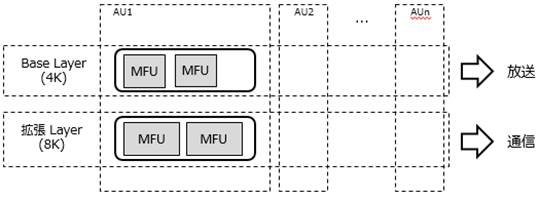
�}�̍ŏ�ʂɂ���l�b�g���[�N���ۉ����C���iNAL�FNetwork Abstraction Layer�j���j�b�g�́AHEVC�iH.265�j�G���R�[�_�[���o�͂��镄�����M���ŁA���܂��܂Ȑ�������܂ޔ�VCL-NAL�ƁA���k���ꂽ�f���X���C�X�f�[�^�ł���VCL�iVideo Coding Layer�j-NAL���j�b�g������B��VCL-NAL���j�b�g�ƍŒ�1��VCL-NAL��A���������̂̓A�N�Z�X���j�b�g�iAU�j�ƌĂ�A1���̃t���[���iPicture�j�ɑ�������B
����MFU�iMedia Fragment Unit�j��MMT�ɂ�����ŏ��̏����P�ʂŁAHEVC�iH.265�j�f���M���̏ꍇ��VCL-NAL���j�b�g��p����B���̏ꍇ��MFU��MPEG-2 TS��PES�ɑ�������B�܂��A�P��܂��͕����̔�VCL-NAL��MFU�ƂȂ�B
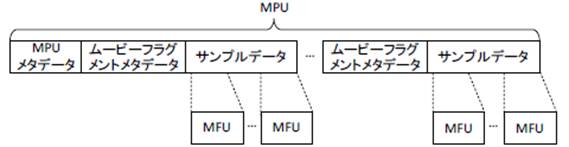
MPU�iMedia Processing Unit�j���} 3‑18�Ɏ����悤�ɁA���^�f�[�^�ƕ����̃T���v���f�[�^�iVCL-NAL���j�b�g�^MFU�j���A���������̂ł���AHEVC�iH.265�j�̂悤�ȃt���[���ԗ\����p���镄�����M����p����ꍇ�ɂ́AGOP�iGroup of Picture�j�Ɠ����P�ʂł���K�v������BMPU�͓Ɨ����ĕ������\�ȕ������P�ʂł���A�����╜��������MPU�P�ʂŎw��\�ł���B
MMTP�y�C���[�h��MPU�^MFU���琶��������@��2����B1�ڂ́AMPU��������@�A2�ڂ�MFU����MPU���\�����鏈�����ȗ����AMFU��MMTP�y�C���[�h�Ƃ�����@�ł���A�����ł͒x�����팸����ړI�����2�ڂ̕��@���p������B���̏ꍇ�AMPU�Ɋ܂܂��ׂ����^�f�[�^�́A������iMMT-SI�j�Ƃ��đ��M�����BMMTP�y�C���[�h�͉ϒ������A�T�C�Y�ɂ�蕡����NAL���j�b�g���i�[����ꍇ��ANAL���j�b�g�����Ċi�[����ꍇ������B
�Ō�ɁAMMTP�y�C���[�h�Ƀw�b�_�[��t������MMTP�p�P�b�g�ƂȂ�B�w�b�_�[�ɂ̓y�C���[�h�^�C�v�A�z�M�^�C���X�^���v�A�p�b�P�[�W�V�[�P���X���̏�܂܂��B
�} 3‑17�@MMT�ɂ����镄�����M���̍\����MPEG-2 TS�Ƃ̔�r
�} 3‑18�@MPU�̈�ʓI�ȍ\��
�i�o�T�FARIB STD-B60�j
3.1.5.4�@ �v���g�R���X�^�b�N
MMT�ɂ���������̃v���g�R���X�^�b�N���} 3‑19�ɁA�܂��ʐM�ł̃v���g�R���X�^�b�N���} 3‑20�Ɏ����BMMT�ł́AIP�̏�ʑw�ƂȂ�UDP��TCP�œ`�������AMMTP�iMMT Protocol�j�p�P�b�g�A����т��̃p�P�b�g���ɕ��������ꂽ���f�B�A���i�[����MMT�y�C���[�h���K�肵�Ă���B
�܂��A���f�B�A�̊e�R���|�[�l�b�g�������`���Ƃ��āAMFU�^MPU���`���Ă���B
MMTP�p�P�b�g�́A�ʐM�ŗ��p����ꍇ��IP�p�P�b�g�����ē`������B�����̓`���H�œ`�����邽�߂ɂ́AIP�p�P�b�g������MMTP�p�P�b�g���ATLV���d��������K�p���ē`������BTLV�ł́A������MMT�̃T�[�r�X�𑽏d���āATLV�X�g���[���Ƃ��ē`�����邱�Ƃ��ł���B�iMMT�ETLV�����j
���̂悤�ɗ��҂̏�ʃ��C�������ʍ\���ł��邽�߁A�����ƒʐM�Ƃl�Ɉ������Ƃ��ł���̂������ł���B
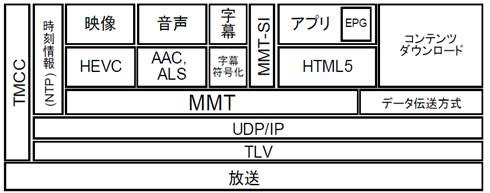
�} 3‑19�@MMT��p��������V�X�e���̃v���g�R���X�^�b�N
�i�o�T�FARIB STD-B60�u�f�W�^�������ɂ����郁�f�B�A�g�����X�|�[�g�����v�j
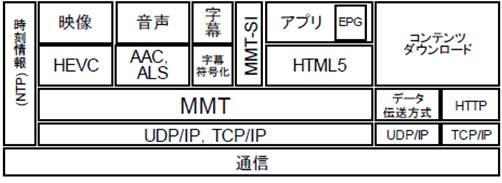
�} 3‑20�@�ʐM����ɂ�����v���g�R���X�^�b�N
�i�o�T�FARIB STD-B60�j
3.1.5.5�@ MMT�p�b�P�[�W
�O���ŋL�ڂ���2�̃v���g�R���X�^�b�N�͔��ɗގ����Ă���A�����MMT�������`���H�ƒʐM�`���H���悤�Ɉ������Ƃ��ł���Ƃ��������ɂ����̂ł���B
�} 3‑21�ɕ����`���H�ƒʐM�`���H�̗�����p����T�[�r�X�̍\���������B�} 3‑21�́A�f���R���|�[�l���g1�A�����R���|�[�l���g1�A�f�[�^1������`���H�ŁA�f���R���|�\�l���g2�A�����R���|�[�l���g2�A�f�[�^2��ʐM�`���H�œ`������`�Ԃ������Ă���B�����`���H�ł͉f���A�����A�f�[�^��3�̃R���|�[�l���g��1��IP�f�[�^�t���[�ɑ��d���A�����TLV�X�g���[���œ`�����Ă���B����́A���M��������ׂĂ̒[���ɓ`������邽�߂ł���B
�܂��A�ʐM�`���H�œ`������R���|�[�l���g�́A�[�����Ƃ̌ʂ̗v���ɉ����邽�߁A�R���|�[�l���g���ƂɈقȂ�IP�f�[�^�t���[�œ`������B
�����ŁA�����T�[�r�X�i�R���e���c�j�ɑΉ����銇����u�p�b�P�[�W�v�ƌĂсA1�̃T�[�r�X�ɂ����ĊJ�n����яI�������ɂ���ʂ����ԑg���u�C�x���g�v�ƌĂԁB
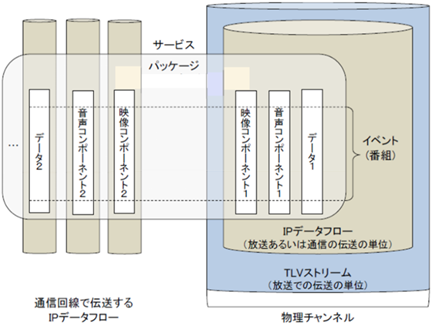
�} 3‑21�@�����E�ʐM���f�ɂ�����T�[�r�X�̍\��
�i�o�T�FARIB STD-B60�j
3.1.5.6�@ MMT���䃁�b�Z�[�W�iMMT-SI�FMMT-Signaling Information�j
MMT-SI�́A�����ԑg�̍\���Ȃǂ������`������M���Ń��b�Z�[�W�E�e�[�u���E�L�q�q��3��ނ���Ȃ�B���b�Z�[�W�̓e�[�u����L�q�q��`�����Ɋi�[���邽�߂̐���M���A�e�[�u���͓���̏��������v�f�⑮�����L�ڂ���������A�L�q�q�͂��ڍׂȏ�������������ł���BMMT�̐��䃁�b�Z�[�W�̌`���Ƃ��AMMTP�y�C���[�h�Ɋi�[��MMTP�p�P�b�g�Ƃ���IP�p�P�b�g�����ē`������B
���b�Z�[�W�̈��PA�iPackage Access�j���b�Z�[�W������A���̒���MPT�iMMT Package Table�j�ŌX�̔ԑg���\������A�Z�b�g�̃��X�g�AURL�����L�q����B
�����̃p�b�P�[�W�i�����R���e���c�j�𑽏d����ꍇ�ɂ́A�} 3‑22�Ɏ����悤��PA���b�Z�[�W�̒��Ƀp�b�P�[�W���X�g�e�[�u�����܂܂�A���̃p�b�P�[�W���X�g�e�[�u���ɑ��̃p�b�P�[�W��MPT���܂�PA���b�Z�[�W��`������MMTP�p�P�b�g�̃��X�g���܂܂��B

�} 3‑22�@�p�b�P�[�W���X�g�e�[�u���ɂ��p�b�P�[�W��MPT�̎Q��
�i�o�T�FARIB STD-B60�u�f�W�^�������ɂ����郁�f�B�A�g�����X�|�[�g�����v�j
3.1.6�@ ACAS
�����Ȃ̓��\�Ŏ�����Ă���VCAS�����̊T�v�ɂ����\ 3‑6�Ɏ����B
�\ 3‑6�@���x�L�ш�q�������iBS/110�xCS�j�̃X�N�����u���T�u�V�X�e��
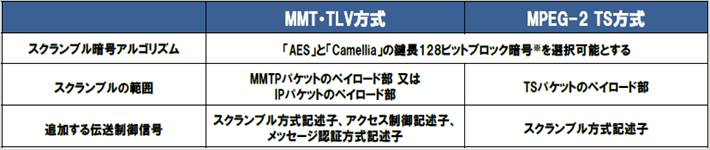
�P�[�u���e���r�ƊE�ł́A2.10���̑�3����STB��4K�^�p�d�l�Ŋ��ɏq�ׂ��悤�ɁA���xBS�ĕ����⍂�x�P�[�u����������ɂ����āA�VCAS�����Ƃ���ACAS��p����B
ACAS�͎��̂悤�ȓ��������B
ž ARIB STD-B61���҂̃A�N�Z�X��������i��2����j�ɏ���
ž �X�N�����u��������AES128�𗘗p���A�Z�L�����e�B������
ž STD-B61���ҋK��̃_�E�����[�_�u��CAS�iD-CAS�j�ɂ͊Y�����Ȃ����ACAS�\�t�g�E�F�A�����S�ɍX�V����d�g�݂�L����
�����ŁAARIB STD-B61���҂ɏ�������ACAS�́A�Z�L�����e�B����̂��߂̏��K�͂ȃ\�t�g�E�F�A�X�V�@�\��L���邪�A���҂ɋK�肳���CAS�v���O�����̑S�ʓI�ȃA�b�v�f�[�g�@�\(D-CAS)�ɂ͑Ή����Ă��Ȃ����Ƃɒ��ӂ��K�v�ł���B
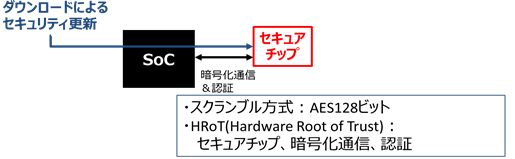
�} 3‑23�@ACAS
�P�[�u���e���r���Ǝ҂�ACAS�𗘗p���邽�߂ɂ́A���p�p�r�ɉ������\ 3‑7�Ɏ���2�̋敪����I�����ē��{�P�[�u���e���r�A����ACAS�X�L�[���ɎQ������B�������A�p�X�X���[�ɂ��ĕ����ɂ�����STB���g�p�����A�����e���r�Ŏ�M����ꍇ�́A�{�X�L�[���̑ΏۊO�ƂȂ�A�X�L�[���ւ̎Q���͕K�v�Ƃ��Ȃ��B
�\ 3‑7�@�A��ACAS���p�X�L�[��

�{�X�L�[���ł́AJ:COM�AJDS�AJCC���VCAS���c��Ƃ̊Ԃ�EMM�iEntitlement Management Message�j���p�ݔ���L����B
J:COM�����JDS�AJCC�P���̎��Ǝ҂́A���̒��p�������āAACAS�V�X�e���Ƃ̊Ԃ�EMM���̂������s���A�VCAS���c��ɑ���EMM�̈Í������˗�����Ƌ��ɁA�A���o�R�ňÍ�����p���x�����B
3.1.7�@ 22.2ch �O�����}���`�`�����l����������
���������ł́A�X�e���I��5.1ch�T���E���h�ɂ���ĉf��ق̂悤�ȗՏꊴ���鉹�������Ɏ�������Ă��邪�A8K�����ł́A22.2ch�O�����}���`�`�����l�������������K�i������A5.1ch�T���E���h�������Տꊴ�̂��鉹�����v�悳��Ă���B
���̕����́A��ԓI�ɔz�u���ꂽ22�`�����l���ƒቹ���ʗp��2�`�����l������\������A3�����I�ȋ�ԉ������Đ�������̂ł���B
5.1ch�����̃X�s�[�J�z�u��
�} 3‑24�ɁA22.2ch�����̃X�s�[�J�z�u���} 3‑25�Ɏ����B����22.2ch������24�̃X�s�[�J�ɂ�鉹����5.1ch�T���E���h�������Տꊴ������A�p�u���b�N�r���[�C���O��V�A�^�[�ȂǂɗL���ł���B
�܂��A�ƒ�ł̂��܂��܂�4K/8K�e���r�������ɑΉ����邽�߂ɁA22.2�}���`�`�����l����������菭�Ȃ��X�s�[�J���ōĐ�����Đ��@�̊J����NHK�����Z�p�������Ői�߂��Ă���A�t���b�g�p�l���f�B�X�v���[�Ɉ�̉����ꂽ12�̃X�s�[�J�ɂ��o�C�m�[�����Đ��@������Ă���Ă���B���̕��@�ł́A24�̃X�s�[�J��ݒu���邱�ƂȂ��A22.2ch�}���`�`�����l��������̌����邱�Ƃ��ł���Ƃ��Ă���B
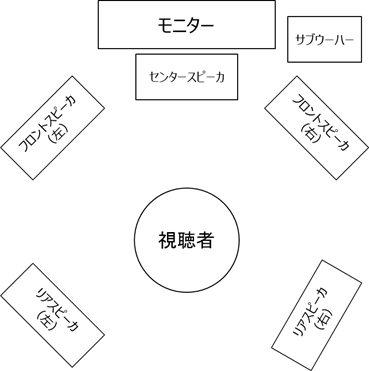
�} 3‑24�@5.1ch�T���E���h�̃X�s�[�J�z�u
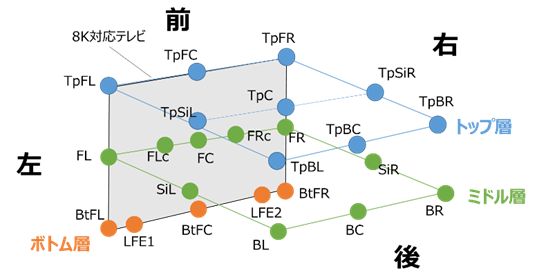
�} 3‑25�@22.2ch�����̃`�����l���z�u�}
3.1.7.1�@ 22.2ch���������̕������K�i
���{�����ɂ�����22.2ch���������ɂ��8K�������������邽�߂ɁA�����ȗߑ�87���u�W���e���r�W�����������̂����f�W�^�������Ɋւ��鑗�M�̕W�������v�̉��肪�s���Ă���B
���xBS�f�W�^�������A���x���ш�CS�f�W�^����������э��x�L�ш�CS�f�W�^�������ɂ�����ő���͉����`�����l�����́A�u22�`�����l������ђ�����������2�`�����l���Ƃ���v���ƁA�����������́A�uMPEG-4 AAC�K�i�����MPEG-4 ALS�K�i�ɏ�����������Ƃ���v���Ƃ��K�肳��Ă���B
�܂��A�����ȗ߁E�����ɑΉ����āAARIB STD-B32�u�f�W�^�������ɂ�����f���������A�����������y�ё��d�������v�̉��肪�s���A�ő�22.2�`�����l���̃}���`�`�����l���������[�h�ɑΉ�����MPEG-4 AAC���������������̂��ڍׂȎd�l�Ɋւ���lj��K�肪�s���Ă���B��ARIB�K�i�ł́A22.2ch������p����Ƃ��ɁA2ch�A5.1ch�����������ɑ���d�g�݂��K�肳��Ă���B
�\ 3‑8�Ɏ����Ƃ���A�ȗ߁E���������ARIB�W���K�i�ɂ����āA8K�����ɗp����T���v�����O���g����48kHz�A�ʎq���r�b�g����16�r�b�g�ȏ�ƋK�肳��Ă���AMPEG-4 AAC������������AAC-LC�iLow Complexity�j�v���t�@�C����p���邱�Ƃ���߂��Ă���B
�\ 3‑8�@22.2ch�����̃f�W�^�������M���K��
|
�T���v�����O���g�� |
48kHz�A96kHz�i�I�v�V�����j |
|
�ʎq���r�b�g�� |
16�r�b�g�A20�r�b�g�A24�r�b�g |
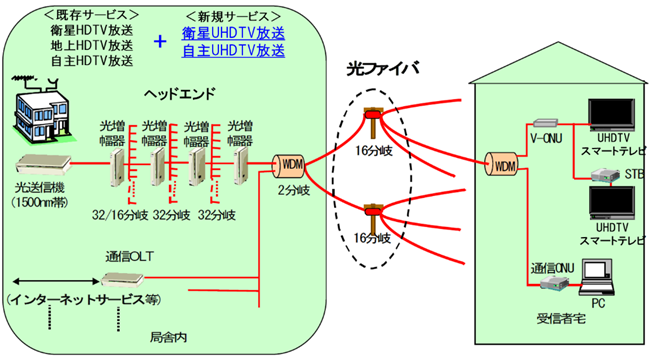
3.1.8�@ 4K�E8K�����̂��߂̓`���Z�p
�q���f�W�^�������ƃP�[�u���f�W�^�������ɂ��Đ�������B���ɁA�P�[�u���f�W�^�������`���Z�p�Ƃ��āA�f�W�^���L���e���r�W�������������iITU-T����J.83 Annex C��64/256QAM�j�A���������g�`�������A�q���f�W�^�������̒��Ԏ��g���iIF�j�p�X�X���[�`�������A����э��x�P�[�u����������ɂ��Ď����B
3.1.8.1�@ �q���f�W�^������
�q���f�W�^�������ɂ́A���x���ш�`�������i���o124/128�xCS�f�W�^�������F�X�J�p�[JSAT�j�ƍ��x�L�ш�`�������iBS/���o110�xCS�f�W�^�������j������A4K�E8K�f�������������ɂ�H.265�iHEVC�j�����������p����邪�A���d��������`���H�������͈قȂ��Ă���B�q���f�W�^�������̍��x���`���Z�p�̊T�v�ɂ��đ����ȃz�[���y�[�W�f�ڎ������Q�Ƃ����\ 3‑9�Ɏ����B
���x�L�ш�q���f�W�^�������̓`���H�����������ł́A���[���I�t����0.1����0.03�ɒጸ���邱�ƂŁA�V���{�����[�g��32.5941Mbaud����33.7561Mbaud�ւƍ��������Ă���A8PSK�i3/4�j�̏ꍇ�A���s�q�������Ɠ����ȏ�̃T�[�r�X���ԗ��Ŗ�72Mbps�̓`�����\�ƂȂ��Ă���B�܂��A�V���������Ƃ���7/9��lj����A16APSK�i7/9�j���̗p���邱�ƂŃg�����X�|���_�������100Mbps�̓`�����\�ł���B�����ʐM�K���̏o�͏���l�i60dBW�j�Ƃ����ꍇ�A16APSK�i7/9�j�ōň����T�[�r�X���ԗ�99.7%�ȏ���m�ۂł���B
�\7-9�ɂ͋K�i��̕����̃p�����[�^��������L�ڂ���Ă��邪�A���xBS�q�������̎��ۂ̉^�p�ɂ�����ϒ�������16APSK�A����������7/9�A�X�N�����u��������AES128�A���d��������MMT�ETLV�A���ƂȂ��Ă���B
�Ȃ��A���o110�xCS�����͉q�������ɔ�׃_�E�������N�d��(e.i.r.p.)�����������߁A��������2/3���g�p���A�g�����X�|���_�������66Mbs�̓`�����\�ƂȂ��Ă���B
�\ 3‑9�@�q���f�W�^�������̍��x���`���Z�p

3.1.8.2�@ �P�[�u���f�W�^������
�f�W�^���L���e���r�W�������������iITU-T����J.83 Annex C��64/256QAM�j�A���������g�`�������A�q��������̃p�X�X���[�`�������i�q���f�W�^��������IF�p�X�X���[�����j�A����э��x�P�[�u����������ɂ��Ď����B
3.1.8.3�@ �����̃f�W�^���L���e���r�W������������
�����̃f�W�^���L���e���r�W�������������iITU-T����J.83 Annex C��64/256QAM�j�ł́AH.265 (HEVC)�AMPEG-2 TS���d���A256QAM��p����4K���p�����i��������j���\�ł���B���̗���} 3‑26�Ɏ����B���̕�����4K�t�H�[�}�b�g�܂ł���{�Ƃ��āA���s�̃P�[�u���e���r�̕����T�[�r�X�Ƃ̑��݉^�p�����ł������m�ۂ��A�����̐ݔ������ő�����p���邱�ƂŁA�P�[�u��UHD TV�����T�[�r�X�̑����̓�������щ^�p���\�Ƃ��邱�Ƃ�ړI�Ƃ��Ă���B
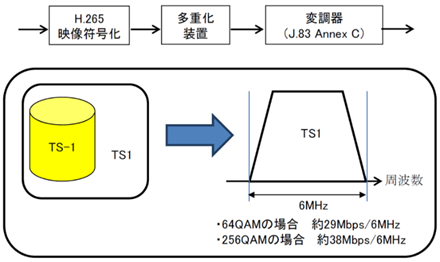
�} 3‑26�@�����̃f�W�^���L���e���r�W�������������ł�4K����
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j
�@ ���������g�`������
J.83 Annex C����{�ɑ�e�ʂ̃f�[�^�𑗂邽�߂̋Z�p�Ƃ��āA����TS�`�������̂P�����g�i64 QAM/256 QAM�j�̓`���e�ʂ���X�g���[���iTS��������TLV�j���̔����g��p���ĕ����`�����A��M�@�ō�����������ł���B����������e�ʃX�g���[���̈ꕔ�Ɗ����̃f�W�^��������TS�p�P�b�g����ʂ��ē���t���[�����ɑ��d�����邱�Ƃ��\�ł���B
���̕����ɂ����p���Ƃ��Ă̓������ȉ��Ɏ����B
(1) �q�������Ɠ����T�[�r�X���P�[�u���e���r�Œ�
ž 64QAM(��30Mbps)��256QAM(��40Mbps)��C�ӂ̕������g���ɐݒ肵�ĕ����`��
ž MMT�ETLV�����MPEG-2 TS�̑o���ɑΉ���
(2) ���s�̃P�[�u���{�݂̐��\��8K UHD TV�`���\
ž ITU-T J.83 Annex C���x�[�X
ž �����g�𑩂˂�����ɂ���e�ʓ`��������
ž ���������g�`�������AITU-T����J.183�𗘗p
ž �����T�[�r�X�̋X���b�g��L�����p�\
�Ⴆ�Βn�f�W�i�g�����X���W�����[�V�����j�̋X���b�g�𑩂˂�4K�`���ȂǁA���s�����ƌ���݊�����L����
(3) ���ۂ̃P�[�u���e���r�{�݂Ŏ��؎����ɐ���
ž ���{�l�b�g���[�N�T�[�r�X�A�R�����@2013�N2��
ž �W���s�^�[�e���R���i���FJCOM�j�A�����s�@2014�N5��
���̕������������邽�߁A�����̕���TS���d�t���[���iTSMF: Transport Stream Multiplexing Frame �j���g������B�ȉ��̐����ł́A�g�����镡��TS���d�t���[�����u�g��TSMF�iExtended TSMF�j�v�Ə̂���B
�܂��A���������g�`�������̐M������M���邽�߁A�V���ɗL�����������g�`�����z�V�X�e���L�q�q�ichannel_bonding_cable_delivery_system_descriptor�j����`���ꂽ�B
�} 3‑27�ɕ��������g�`�������̊T�v�������B
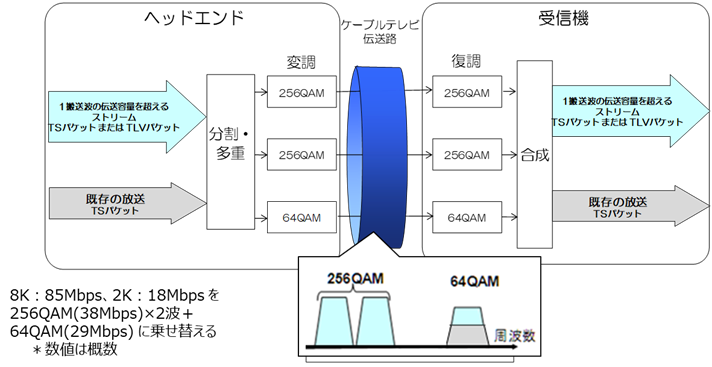
�} 3‑27�@���������g�`�������̊T�v
�i�g��TSMF��K�p����2��256 QAM��1��64 QAM����`�������j
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�
�����V�X�e���ψ���P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j
�A �ϒ���������ѓ`���H����������
���������g�`�������ő��M���镪�������X�g���[���̓`���H�����������́A�����̃f�W�^���L���e���r�W�������������̓`���H�����������Ɠ���Ƃ���B�V���{���N���b�N�͔����g�Q���\������e�����g�œ������Ă�����̂Ƃ���B
���������g�`�������̊e�����g�́A�����̃f�W�^���L���e���r�W�������������Ɠ���̓`���H�����������i�ϒ������A���[���I�t���A�G�l���M�[�g�U�����A�����������A�C���^�[���[�u�����A�t���[�������M���A�t���[���\���j��p����B����ɂ��A�} 3‑28�Ɏ����悤�ɁA�����̃f�W�^���L���e���r�W�������������Ɠ����M���`���Ƃ��ď������邱�Ƃ��\�ł���A����܂łɊJ�����Ă����Z�p��K�i�����p���邱�Ƃ��\�ł��邱�Ƃ��A���؎����ɂ��m�F����Ă���B
�擪�o�C�g�̒l��0x47��188�o�C�g�̃f�[�^����̗p���邱�Ƃɂ��A�P��TS�`�������╡��TS�`�������Ɠ��l�ɁA���������g�`�������������̓`���H�����������ň������Ƃ��\�ł���B�����g�Q���\������e�����g�̃V���{���N���b�N�������邱�Ƃő���M�@�̍\�����ȑf���ł���B
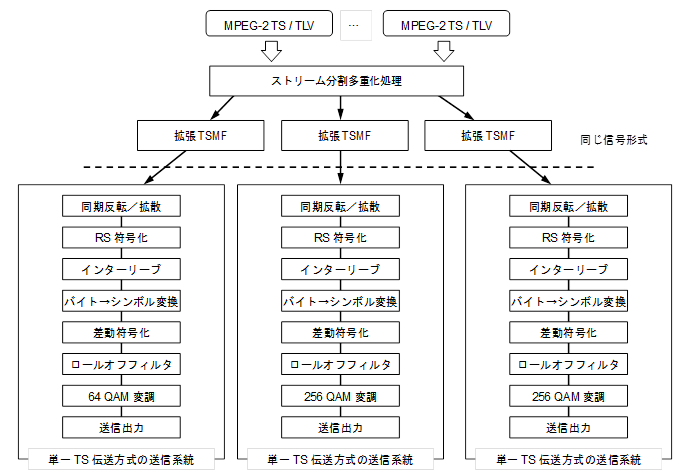
�} 3‑28�@���������g�`������
�i��e�ʂ̃X�g���[����1��64 QAM��2��256 QAM�ɕ������ē`�������j
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j
(1) 4K�A8K�T�[�r�X�̓`����
4K 8K�����������悭�������鉞�p��Ƃ��āA�} 3‑29��4K��2K���ꂼ��1�`�����l����`���������A�܂��} 3‑30��8K��2K�����ꂼ��1�`�����l���`�������������B
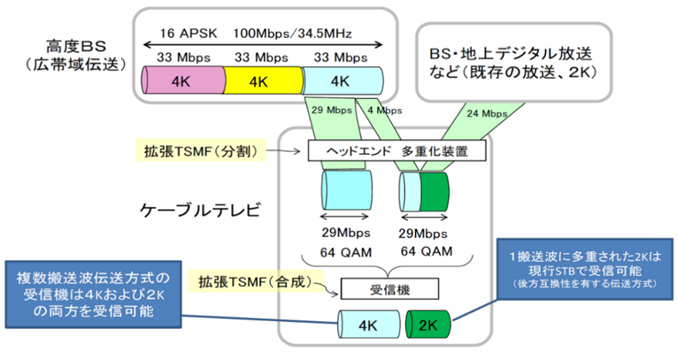
�} 3‑29�@4K��2K���ꂼ��1�`�����l����`��������{��
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j

�} 3‑30�@8K��2K���ꂼ��1�`�����l����`��������{��
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j
(2) ��e�ʂ�TS�p�P�b�g��`������Z�p
4K�A8K�Ȃǂ̑�e�ʂ�TS�p�P�b�g�܂���TLV�����p�P�b�g��`�����邽�߂ɕ��������g�ɕ������ē`�����鉞�p��Ƃ��Ĕ����g�Q�ɑ���������g�̕ϒ��������������ꍇ�̃X���b�g�̔z�𑗐M���M���A���d�����u�A��M�@���M���ɕ����Ă��ꂼ���} 3‑31�A�} 3‑32�A�} 3‑33�Ɏ����B
|
���M��TS�@ |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
8 |
9 |
![]() �@�@�@�@�@�@�@�@�@�@�@�@�@�@����
�@�@�@�@�@�@�@�@�@�@�@�@�@�@����
�} 3‑31�@���M��TS�M���𑗐M�O�̃X���b�g�̔z�C���[�W�i100Mbps�j
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�@�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j

![]() �@�@�@�@�@�@�@�@�@�@�@�@�@�@����
�@�@�@�@�@�@�@�@�@�@�@�@�@�@����
�} 3‑32�@�����g�Q�ɕ��������X���b�g�̔z�C���[�W�i25Mbps�~4ch�j
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�@�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j
|
��M������TS�@ |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
![]() �@�@�@�@�@�@�@�@�@�@�@�@�@����
�@�@�@�@�@�@�@�@�@�@�@�@�@����
�} 3‑33�@��M��TS�M���𑗐M�O�̃X���b�g�̔z�C���[�W�C���[�W�i100Mbps�j
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�@�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j
(3) TLV�M���̊g��TSMF�ւ̑��d��
�g��TSMF���d�����u�́ATS�M�����̓|�[�g�ɓ��͂���TS�M����������TLV�M�����̓|�[�g�ɓ��͂���TLV�M�����A�g��TSMF��̃X���b�g�ɁA����TS�M���������͓���TLV�M���̓Ɨ�����ۂ��Ȃ��瑽�d�����A�o�͂�����̂ł���B
���d������TLV�M���Ɋ܂܂��TLV-NIT���P�[�u���e���r�l�b�g���[�N�i���l�b�g���[�N�j�p�̂��̂łȂ��Ƃ��́A�P�[�u���e���r�l�b�g���[�N�i���l�b�g���[�N�j�p�ɏ���������TLV-NIT��TLV�M���ɑ}�����ďo�͂���B
TLV�M���́A�ϒ���TLV�p�P�b�g�̏W���ł���B�g��TSMF���d�����u�ł́ATLV�p�P�b�g���Œ蒷�i188�o�C�g�j�̕���TLV�p�P�b�g�ɕϊ����A�X���b�g�ɑ��d����B����TLV�p�P�b�g�́A�擪��3�o�C�g���w�b�_�[�Ƃ��A����ɑ���185�o�C�g���y�C���[�h�Ƃ���B
�} 3‑34��TLV�p�P�b�g�����āA����TLV�p�P�b�g������������������B�y�C���[�h�ɂ́A�������ꂽ������TLV�p�P�b�g���܂܂�邱�Ƃ�����B
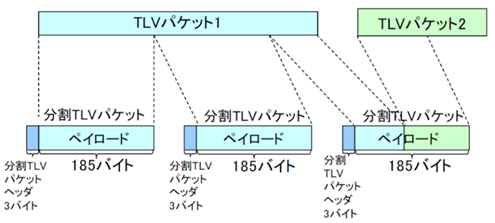
�} 3‑34�@����TLV�p�P�b�g�̗�
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�@�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j
�Q�l�Ƃ��āA�g��TSMF���d���̋@�\�u���b�N�\������} 3‑35�Ɏ����B�g��TSMF���d�����u�ł́A����TLV�M���̓`�����x�ɑ��āA����������Ȃ����o�\�Ƃ���X���b�g�������炩���ߊm�ۂ��Ă����B���Z���ꂽ�`�����x������TLV�M���̓`�����x������ꍇ�ɂ́A�k��TLV�p�P�b�g��}�����đ��x�������s���A�m�ۂ��ꂽ�X���b�g�̂��ׂĂ�TLV�p�P�b�g�Ŗ��߂Ȃ��Ă͂Ȃ�Ȃ��B
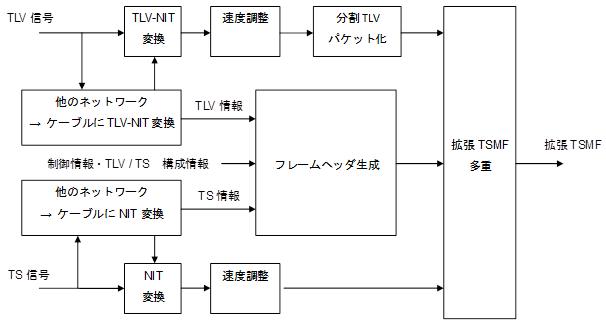
�} 3‑35�@TS�M�������TLV�M�����g��TSMF���d����\����
�B IF�p�X�X���[�`������
FTTH�����Ă���V�X�e���ɂ����ẮAIF�p�X�X���[�����ɂ��4K�E8K�̕�����`�����邱�Ƃ��\�ł���B���x�L�ш�q���f�W�^������������16APSK�ϒ������ɂ����ẮA��������������9/10�̎��ɗv��������M�Ғ[�q�ɂ�����C/N�́A17dB�ȏ�ŁA���̐M�����P�[�u�����Ǝ҂���M���āAIF�p�X�X���[�����ɂ��ĕ����T�[�r�X���s�����߂ɂ́A���s�K�i�̕W���q���f�W�^���e���r�W����������IF �p�X�X���[�K�i11dB����6dB����C/N���m�ۂ���K�v������B�} 3‑36�ɉq��������̃p�X�X���[�`�������ɂ�����T�[�r�X��������B
IF�̍ō����g���́AND-23��`������Ɩ�3224MHz�ƂȂ�B�S�Ă�IF���g���́A�\ 3‑10�ɋL�ڂ���Ă���B
�} 3‑36�@�q��������̃p�X�X���[�`�������ɂ�����T�[�r�X��
�i�o�T�F���ʐM�R�c��@���ʐM�Z�p���ȉ�@�����V�X�e���ψ���
�@�P�[�u���e���rUHDTV��Ɣǁ@�i�āj�j
�ȉ��ɁA�A���e�i�ɂ��q�������g�̎�M��q��������̃p�X�X���[�`���Ɋ֘A�����Q�l���������B
�q�������g�̉~�Δg�Ƃ́A�}7-37�Ɏ����悤�ɕΔg�ʂ���]���Ă�����̂������B�����Δg�␂���Δg�����A�q���̎p���ɂ��Δg�����̕ω�����̉e�����ɂ����B
�~�Δg�ɂ��ẮA�d�g�̐i�s�����Ɍ������Ď��v���̉E���~�Δg�Ɣ����v���̍����~�Δg������B�E���ƍ����̓d�g�݂͌��Ɋ����Ȃ����߁A�q�������g�ɂ����Ă͓������g���т����p���邱�Ƃ��\�ł���B���݂̕����Ɏg���Ă���͉̂E���݂̂ł��邪�A�������g�p���J�n���ꂽ�B�P�[�u����ɂ����ẮA�������g���т̋��p�͕s�\�ł��邽�߁A�݂��ɈقȂ���g���ɕϊ����ē`�������B
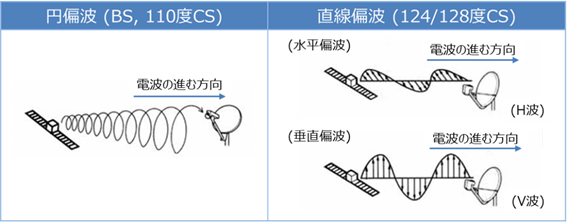
�} 3‑37�@�q�������g�̕Δg���i�o�T�F�q����������j
�} 3‑38�̓P�[�u����Ŏg�p����IF�ւ̎��g���ϊ��̌����������Ă���B�q�������g�ƉE���p���邢�͍����p�̋Ǖ����M���g���Ƃ��������A�����g���������t�B���^�őI�ʂ���IF�����o���B�Ȃ��A�����p�̋Ǖ����U���g����ARIB STD-B63�ɂ����ĉ��肳��Ă���A�]����ARIB STD-B21�����̃A���e�i�Ƃ͌݊����������̂Œ��ӂ��K�v�ł���B
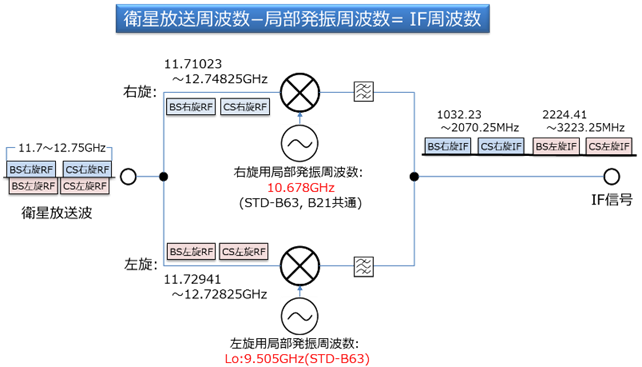
�} 3‑38�@BS/110�xCS�@IF�ւ̎��g���ϊ� �i�o�T�FARIB STD����}�j
�\ 3‑10�́ABS/110�xCS-IF�̎��g���ꗗ�ł���B���̕\�Ɏ����悤�ɁA�����~�Δg�̗��p�ɂ�葽����IF���lj�����Ă���A�P�[�u����ɂ�����ō��`�����g����3223.25MHz�ƂȂ����B���̂悤�ȍ������g���ɂ�����M�����x����C/N���m�ۂ��邽�߂ɁA����E�����̓����P�[�u���A�u�[�X�^�A���z��A�e���r�[�q�Ȃǂ̌�����Ƃ��K�v�ƂȂ�ꍇ������B
�\ 3‑10�@BS/110�xCS-IF���g���ꗗ
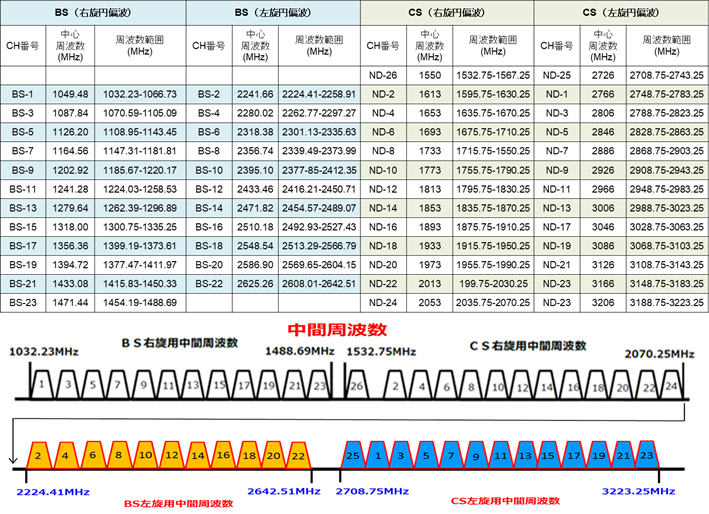
�\ 3‑11�́A���̂悤��IF���p�X�X���[�`�����邽�߂ɒ�߂�ꂽ�Z�p��ł���B
�\ 3‑11�@�q��������̃p�X�X���[�`�������̎�ȋZ�p�
3.2�@ IoT�T�[�r�X
3.2.1�@ �C���g���_�N�V����
IoT�iInternet of Things�j�Ƃ́A�قȂ��ނ̕����I�ȃf�o�C�X��I�u�W�F�N�g���C���^�[�l�b�g�ɐڑ�����A���݂ɒʐM���A�f�[�^����������Z�p��T�O�łł���BIoT�́u���m�̃C���^�[�l�b�g�v�Ƃ��Ă�A���퐶����Y�Ɗ����ɂ����āA�l�X�ȕ��i���C���^�[�l�b�g����đ��݂ɘA�g���A�������L���邱�Ƃ��\�ɂ��Ă���B
��̓I�ɂ́A�Z���T��A�N�`���G�[�^�[�𓋍ڂ����f�o�C�X���A�l�b�g���[�N�ɐڑ�����A���A���^�C���Ńf�[�^�����W���A�������A������s���B����ɂ��A���Y���̌���A�������A�������A�T�[�r�X�̉��P�Ȃǂ̗l�X�ȗ��_�����҂����B
IoT�̊�ՂƂȂ�Z�p�ɂ́A�Z���T�Z�p�A�l�b�g���[�N�Z�p�A�N���E�h�R���s���[�e�B���O�A�r�b�O�f�[�^�����A�l�H�m�\�Ȃǂ��܂܂��B�����̋Z�p����������邱�ƂŁAIoT�V�X�e������������A�V���ȃr�W�l�X���f����T�[�r�X�̐��������҂���Ă���
IoT�̗��j�͌Â��B�C���^�[�l�b�g���l�̃R�~���j�P�[�V�����݂̂��痣��͂��߂��̂́A1990�N�㏉���Ƀ}�[�N�E���C�U�[�iMark Weiser�j�ɂ���Ē��ꂽ�h���r�L�^�X�R���s���[�e�B���O�h�����[�Ǝv����B�ނ́A1991�N�ɔ��\�����_���ŁA�R���s���[�^���l�X�̓��퐶���ɐZ�����A�ڂɌ����Ȃ��`�Ől�X�̎��͂ɗn������Ŏg����悤�ɂȂ邱�Ƃ��N�����B
1990�N��㔼����2000�N�㏉���ɂ����ẮA���r�L�^�X�R���s���[�e�B���O�̎����ƌ����̐i�W������ꂽ�B���ɓ��{�ł̓��r�L�^�X�l�b�g���[�N�Ƃ������ōL���m��킽��A���ɂ�鐔�����̌����J�����J�Ԃ����B����ɂ́A�Z���T�e�N�m���W�[�̐i���A���o�C���R���s���[�e�B���O�̕��y�A3G�g�ѓd�b�V�X�e�����͂��߂Ƃ��郏�C�����X�ʐM�Z�p�̔��W�̍v�����傫��
IoT�̗p�ꂪ���Ɍ��ꂽ�̂́A�����炭IUT-T�ɂ��hThe Internet of Things�h(ITU INTERNET REPORTS2005)[1]����ł͂Ȃ����A�Ǝv����B���̒��ł͒ʐM�̑Ώۂ��@�B��Z���T�܂Ŋg�傳��A��������̂��l�b�g���[�N�Ɍq����֘A����R���e���c�������p���_�C��������B
2000�N�㒆������́A�Z���T�Z�p�̐i����4G/Wi-Fi�ʐM�Z�p�̔��W�Ɏx�����A�l�X��IoT�f�o�C�X���J������A���y���݂����B���ɁA�X�}�[�g�Ɠd�A�X�}�[�g���[�^�A�����Ԃ̃e���}�e�B�N�X�ȂǁA������Y�Ƃ̂��܂��܂ȕ����IoT�����p����n�܂����̂����̍�����ł���B
2010�N�㒆���ȍ~�AIoT�̓f�[�^�쓮����|�ɐi�����n�߂�BIoT�f�o�C�X�����W����f�[�^�ʂ͋}���ɑ������A�C���^�[�l�b�g��ɑ�ʂɗ���n�߂�B������r�b�O�f�[�^�Z�p��N���E�h�R���s���[�e�B���O���x���A�f�[�^���͂�@�B�w�K�����p�������l�n�����s����悤�ɂȂ��Ă������B�������̗����̍����f�[�^������Ղ��o�����A�f�[�^�����r�����i��ł������B����ł́A�Z�L�����e�B�̏d�v���������AIoT�f�o�C�X��l�b�g���[�N�̃Z�L�����e�B��������Ă������B
����́AIoT�̏�����Ղ͂قڊm�����A�G���h�̃Z���T���m�I�Ȑi�����i��ł���B�N���E�h�݂̂ɗ��炸�A�Z���T�߂��ł̏������d������G�b�W�R���s���[�e�B���O��l�H�m�\�iAI�j�Ȃǂ̐V���ȋZ�p������IoT�ɓ�������A���A���^�C���ł̃f�[�^�����⓴�@�̒����҂���悤�B
3.2.2�@ IoT�̊�ՋZ�p
IoT���\�������ȋ@�\�v�f�Ƃ��ẮAIoT���x�����ՂƂ��ẮA�傫�������āA�Z���T/�G���h�f�o�C�X�A�Z���T�m�[�h�A�ʐM�l�b�g���[�N�A�N���E�h�v���b�g�t�H�[���A�����ăf�[�^���͏����A�A�v���P�[�V����/���[�U�[�C���^�[�t�F�[�X�A�Z�L�����e�B�A����/�A�N�`���G�[�V���@�\�ɂȂ�ƍl������B�ȉ������ɂ��ĊT������B
3.2.2.1�@ �Z���T
IoT�ŗ��p�����Z���T�́A���܂��܂Ȏ�ނ�����A�l�X�ȗp�r�ɉ����ăf�[�^�����W����B�ȉ��ɁA��ʓI��IoT�Z���T�̎�ނƂ��̗p�r��������������B
���x�Z���T:
���x�𑪒肵�A���̉��x�ω����Ď�����B�ƒ��Y�Ɨp�r�ł̋C��Ǘ��A�①�ɂ�Ⓚ�ɂ̉��x�Ǘ��ȂǂɎg�p�����B
���x�Z���T:
���x�𑪒肵�A���C�⊣���̏�Ԃ��Ď�����B�ƒ��Y�Ɨp�r�ł̎��x�Ǘ���A�A���͔|�̃��j�^�����O�ȂǂɎg�p�����B
���Z���T:
���̗ʂ𑪒肵�A�Ɩ�����̖��邳������B�܂��A�����̗ʂ𑪒肵�āA���z�����d�V�X�e���̍œK�Ȕz�u�����肷��̂ɂ��g�p�����B
�����x�Z���T:
���̂̉����x�𑪒肵�A�U���⓮�������o����B�X�}�[�g�t�H����E�F�A���u���f�o�C�X�Ȃǂ̓��쌟�o��A�n�k�̃��j�^�����O�ȂǂɎg�p�����B
���̓Z���T:
���͂𑪒肵�A�C���␅���̕ω����Ď�����B�V��\���⍂�x�̌v���A�����̃��j�^�����O�ȂǂɎg�p�����B
�����Z���T:
���̂܂ł̋����𑪒肵�A��Q�����m��ʒu����ȂǂɎg�p�����B�����Ԃ̒��Ԏx���V�X�e����{�b�g�̏�Q������Ȃǂɗ��p�����B
�K�X�Z���T:
����̃K�X�̔Z�x�𑪒肵�A�K�X�R���������̊Ď����s���B�R���K�X���m����C�i���Z���T�Ȃǂ�����B
�����Z���T:
���͂̉��𑪒肵�A���ʂ���g���͂���B�����F���V�X�e������Ď��ȂǂɎg�p�����B
3.2.2.2�@ �Z���T�m�[�h
IoT�Ŏg����Z���T�m�[�h�Ƃ́A�Z���T�ƒʐM�@�\��g�ݍ��킹�����^�̃f�o�C�X���w���B�Z���T�m�[�h�́A�Z���T�ߖT�ɔz������A��ɃZ���T�Ƃ̃C���^�t�F�[�X�A�}�C�N���R���g���[���A�ʐM���W���[���Ȃǂ���\������A�Z���V���O�����f�[�^��K�ɃN���E�h�ɑ��邱�Ƃ�ړI�Ƃ��Ă���B
�Z���T�m�[�h�̑�\�I�ȗ�Ƃ��ẮAArduino����������BArduino�́A�I�[�v���\�[�X�v���b�g�t�H�[���ŁA�}�C�N���R���g���[���[�𒆐S�Ƃ����n�[�h�E�F�A�ƁA������v���O�������邽�߂�Arduino IDE�ƌĂ��\�t�g�E�F�A�J��������\�������BArduino�{�[�h�́A�Z���T��A�N�`���G�[�^�Ȃǂ̎��Ӌ@���ڑ����A���䂷�邽�߂̃v���g�^�C�s���O��n�[�h�E�F�A�J���ɍL���g�p����Ă���B�} 3‑39��Adruino UNO�̎ʐ^�ł���B

�} 3‑39�@Arduino�{�[�h(WikiPedia�����p).
Arduino�ƕ���ōL�����p����Ă���Z���T�m�[�h����R�X�g�ŏ��^�̃V���O���{�[�h�R���s���[�^Raspberry Pi�ł���BRaspberry Pi�́A�L�x��GPIO�iGeneral Purpose Input/Output�j�s����USB�|�[�g������A���܂��܂ȃZ���T��f�o�C�X��ڑ����Ďg�p���邱�Ƃ��\�ł���BLinux�x�[�X�̃I�y���[�e�B���O�V�X�e��(e.g., Raspberry Pi OS)�����s���APython�₻�̑��̃v���O���~���O����ŊJ�����邱�Ƃ��\�ł���B������Raspberry Pi�͊ȒP��IoT�����p�ƍl�����Ă������A�p�t�H�[�}���X���o�[�W�������オ�閈�ɐi�����AGPU�����ڂ����Ɏ����Ă���(2024�N1�����_�ł�Raspberry Pi 5�����\����Ă���)�B�܂�Raspberry Pi OS�ɂ͐��������\�t�g�E�F�A�ł���Wolfram�Ђ�Mathematica�������Ńo���h������Ă��邱�Ƃ����M�����B

�} 3‑40�@Raspbery Pi 4 Model B�iWikiPedia�����p�j
��y��IoT�p�̃Z���T�m�[�h�Ƃ��ė��p�\�ȃ}�C�N���R���g���[���{�[�h�Ƃ��ẮAESP8266�����ESP32������B������WiFi��Bluetooth������AArduino IDE�Ńv���O���~���O���邱�Ƃ��ł��A�����̊J���҂�R�~���j�e�B�Ɏx������Ă���B

�} 3‑41�@ESP32���W���[���̗�iWikiPedia���j
�@�܂��ŋ߂ł�NVIDIA�Ђ��GPU�𓋍ڂ����g�ݍ���IoT�A�v���P�[�V�����ɂēK�p�\��Jetson Nano����������A��q����悤�ȃZ���T�m�[�h�ł�AI�������\�ɂ��Ă��Ă���B
3.2.2.3�@ �X�}�[�g�f�o�C�X
�@IoT�A�v���P�[�V�����ł͂��܂��܂ȃZ���T�@�\��A�N�`���G�[�^�@�\��������X�}�[�g�f�o�C�X���悭���p�����B�����ł͂��̗��������B
�X�}�[�g�z��
���͂�R���f�B�e�B�Ƃ��āA����K�v���Ȃ����AiPhone��Android�[���̂悤�ȃX�}�[�g�z���́A�^���Ȃ�����̑�\�I�ȃX�}�[�g�f�o�C�X�ł���B�@�\�I�ȃ��[�U�C���^�t�F�[�X�A�l�b�g���[�N�T�[�r�X�@�\�AGPS�A�ʐM�@�\�A�Z�L�����e�B�@�\��������A�l�X�̐������x����K�{�̃c�[���ƂȂ����BIoT�̊ϓ_����́A���[�U�ւ̃��[�`���x����Ӗ��ŕK�{�f�o�C�X�ł���B
�X�}�[�g�X�s�[�J
Amazon Echo�AGoogle Home�AApple HomePod�Ȃǂ̃X�}�[�g�X�s�[�J�[�́A�����A�V�X�^���g�𓋍ڂ��A�����R�}���h���t���A���[�U���v��������̒�ƒ���̋@���T�[�r�X�̐�����s�����Ƃ��ł���B
�X�}�[�g�Ɩ�
Philips Hue�ATP-Link�Ȃǂ̃X�}�[�g�d���́A�X�}�[�g�t�H���≹���A�V�X�^���g����āA���邳��F���x��������A�^�C�}�[��ݒ肵���肷�邱�Ƃ��\�ł���B
�X�}�[�g�R���Z���g
SwitchBot��TP-Link�Ȃǂ̃X�}�[�g�R���Z���g�́A�Ɠd���i�������[�g�ŃI��/�I�t������A����d�͂����j�^�����O�����肷�邱�Ƃ��\�ł���B
�X�}�[�g�J����
TP-Link���e�Ђ������Ă���X�}�[�g�J�����́A�l�b�g���[�N�@�\��L���Ă���A���A���^�C���ʼnƂ̒���O�̏����j�^�����O������A���������m���ăA���[�g�𑗐M������ł��A������h�ƂɍL�����p����Ă���B
�G�A�^�O
�u�G�A�^�O�v�́AApple���J���������^�y�ʂ̒ǐՃf�o�C�X�ŁA�����ɂ́uAirTag�v�ƌĂ�A���������茩���ɂ������i��ǐՂ��邽�߂ɗp������B�ʐM��i�Ƃ��Ă�Bluetooth��Ultra Wideband�iUWB�j�̋Z�p��g�ݍ��킹�ē��삳����BBluetooth�ŋߋ����Ń��[�U�[��iPhone�ƃy�A�����O���AUWB���g�p���āA�G�A�^�O�̐��m�Ȉʒu����肷��B
3.2.2.4�@ �E�F�A���u���f�o�C�X
�X�}�[�g�f�o�C�X�̈��ł��邪�B���ɐl�ɑ������ėp��������̂̓E�F�A���u���f�o�C�X�ƌĂ��B��\�I�ȃf�o�C�X������������B
�@ �X�}�[�g�E�H�b�`
�X�}�[�g�E�H�b�`�́A�r�ɑ�������f�o�C�X�ŁA���v�̋@�\�����łȂ��A���N��t�B�b�g�l�X�̃g���b�L���O�A�ʒm�̎�M�A���y�̍Đ��A���ϓ��̋@�\�����B��\�I�Ȃ��̂�Apple Watch������B
�A �t�B�b�g�l�X�o���h
�t�B�b�g�l�X�o���h�́A����r�ɑ�������f�o�C�X�ŁA�^���⊈���ʁA�����Ȃǂ̌��N�����g���b�L���O���A���[�U�[�̌��N�Ǘ���t�B�b�g�l�X�ڕW�̒B�����x������B��\�I�Ȃ��̂�Google��Fitbit������B
�B �X�}�[�g�O���X
�X�}�[�g�O���X�́A���K�l�̂悤�Ȍ`��̃f�o�C�X�ŁA�f�B�X�v���C��J�����A�Z���T�𓋍ڂ��A���̕\����AR�i�g�������j�̌������B��Ƃ��Ă̓Z�C�R�[�G�v�\������������MOVERIO�����Ă���B
�C �E�F�A���u���J����
�E�F�A���u���J�����́A�g�ɒ����邱�Ƃ��ł���J�����ŁA�A�N�e�B�r�e�B��C�x���g���L�^���A�n���Y�t���[�ł̎B�e�⓮��z�M���s����BGoPro���L���ł���B
�D �E�F�A���u���w�b�h�Z�b�g
�E�F�A���u���w�b�h�Z�b�g�́A�����ɑ�������f�o�C�X�ŁA�����̎�M��M�A���z�����iVR�j��g�������iAR�j�̌������BMeta������Meta Quest��Microsoft������HoloLens���L���ł���B
3.2.2.5�@ �ʐM�Z�p
IoT�ł̓Z���T�������U���Ĕz������邱�Ƃ������A������萶����������K�ɏW�邽�߂ɒʐM�Z�p�͂قڕK�{�ƂȂ��Ă���BIoT�A�v���P�[�V�����̏ꍇ�A�ʐM�����͂��قǒ����Ȃ��Ă��悭�A�`�����x���ᑬ�ŗǂ�����ɒ����d�͂������v������邱�Ƃ������B�����ł͂�������\�I�ȋZ�p�����B
�@ Wi-Fi
Wi-Fi�́A����LAN�𗘗p�����ʐM�Z�p�ł���A�ƒ��I�t�B�X�Ȃǂ̉������ł悭�g�p����A���������肵���ʐM�����B�ŋ߂ł�Wi-Fi6��Wi-Fi6E�Ȃǂ̍L�ш�ȕ������o�����Ă����B
�A Bluetooth
Bluetooth�́A�ߋ��������ʐM�Z�p�ł���A�X�}�[�g�t�H����X�}�[�g�E�H�b�`�Ȃǂ̃f�o�C�X�Ԃł̐ڑ��ɍL���g�p����Ă���B�ȓd�͒ʐM��ړI�Ƃ���Bluetooth Low Energy�iBLE�j�Ȃǂ̋K�i���o�ꂵ�Ă���B
�B Zigbee
Zigbee�́A�����d�͂̃f�o�C�X�Ԃł̒ʐM�ɓ������������ʐM�K�i�ł���A�X�}�[�g�z�[����Y�Ɨp�r�ōL���g�p����Ă���B���b�V���l�b�g���[�N�̍\�z���\�ł���B�Ȃ��ߋ���/�����d�͂���������ʐM�����Ƃ��ẮAZ-Wave��ANT�Ȃǂ�����B
�C LPWA
LPWA(Low Power Wide Area)�͒������ł̒ʐM���\�ɂ�������d�̖͂����ʐM�Z�p�ł���A�L��̃Z���T�l�b�g���[�N�̍\�z�Ɏg�p�����B�Y�Ɨp�r��_�ƁA�s�s�C���t���̃��j�^�����O�Ȃǂŗ��p����邱�Ƃ������BLPWA�ɂ͊e��̃V�X�e��������ALoRa, LoRaWAN, NB-IoT, Sigfox, ELTRES, ZETA�Ȃǂ��m���Ă���B
3.2.2.6�@ �ʐM�v���g�R��
IoT�ł́A�`��������͑��̃A�v���P�[�V�����ɔ�ׂ����Ώ��ʂł��邱�Ƃ������B���̂��߁A�ʐM�ɗp������v���g�R���͌y�ʂł����ʂ̃f�[�^�p�ɃI�[�o�[�w�b�h�̏��Ȃ����̂��p������B��\�I�ȒʐM�v���g�R���Ƃ��Ă͉��L�̂悤�Ȃ��̂�����B
�@ MQTT (Message Queuing Telemetry Transport)
���Ƃ���IBM�ɂ���ĊJ�����ꂽ�y�ʂȃ��b�Z�[�W���O�v���g�R���ŁAIoT�f�o�C�X�Ԃ̒ʐM�ɍL���g�p����Ă���B��ш敝��s����ȃl�b�g���[�N���ł������I�ɓ��삵�A������p�u�T�u�iPublish/Subscribe�j�ƌĂ��A�ԂɃu���[�J����郂�f�����̗p���Ă���B
�A HTTP (Hypertext Transfer Protocol)
�E�F�u�A�v���P�[�V�����ōL���g�p�����W���I�ȃv���g�R���ł����ARESTful�ȍl���������邱�ƂŁA�Z���T�̒l��₢���킹�ē���Ȃ�IoT�f�o�C�X�Ԃ̒ʐM�ɂ��L�����p����Ă���BRESTful API���������邱�ƂŁA�f�o�C�X�Ԃ̃f�[�^��������p�ӂɍs�����Ƃ��ł��܂��B
�B CoAP (Constrained Application Protocol)
HTTP�͔�r�I�d���v���g�R���ł��邽�߁A�@�\���y�ʉ������v���g�R���ł���BIoT�f�o�C�X��Z���T�l�b�g���[�N�ł̒ʐM�ɓK���Ă���BUDP��œ��삵�ARESTful�ȃC���^�t�F�[�X����Ă���B
�C AMQP (Advanced Message Queuing Protocol)
���b�Z�[�W�w���~�h���E�F�A�V�X�e�������ɁAMQTT�Ɠ��lPublish/Subscribe ������p�����v���g�R���ł���B��{�͋��Z�@�ւł̃V�X�e���̂悤�ȃ��b�Z�[�W�L���[�̈��S�ȓ]����z�M���s�����߂Ɏg�p����邪�AIoT�V�X�e���ɂ����Ă��A�M�����̍����ʐM����������ۂɗ��p�����B
3.2.2.7�@ IoT�Ɏg����f�[�^�t�H�[�}�b�g
IoT�ŗp������f�[�^�t�H�[�}�b�g�Ƃ��ẮA�y�ʂł��ǐ��ɗD�ꂽ�t�H�[�}�b�g���]�܂��B��\�I�Ȃ��̂Ƃ��ĉ��L����������B
�@ JSON (JavaScript Object Notation)
�y�ʂŐl�Ԃɂ��ǐ��������f�[�^�t�H�[�}�b�g�ŁA�L�[�ƒl�̃y�A����Ȃ�e�L�X�g�x�[�X�̌`���ł���BWeb�A�v���P�[�V������RESTful API�ȂǂōL���g�p����Ă���B
�A XML (eXtensible Markup Language)
�\�������ꂽ�f�[�^��\�����邽�߂̃}�[�N�A�b�v����ŁA�^�O�Ɨv�f����Ȃ�e�L�X�g�x�[�X�̌`���ł���B�E�F�u�T�[�r�X��f�[�^�̌����t�H�[�}�b�g�Ƃ��čL���g�p����Ă������A�ߔN��JSON�Ɏ���đ����邱�Ƃ������Ă���B
�B Protocol Buffers (protobuf)
Google���J�������o�C�i���`���̃f�[�^�t�H�[�}�b�g�ŁA�v���g�R���o�b�t�@�Ƃ��Ă��B�����I�ȃf�[�^�̒���(�K�w�������Ȃ��t���b�g�Ȉ�Ȃ���̃f�[�^�ɕϊ�����)��t�����������A�v���g�R���o�[�W�����Ǘ���f�[�^�\���̊g��������Ă���B
�C RDF(Resource Description Framework)
�@RDF�̓f�[�^���O���t�\���ŕ\�����߂̕\�L�@�ŁA�g���v���b�g�Ƃ��ĕ\�����ꂽ����p���ăf�[�^���f����\������B�Ӗ���\���ł���Z�}���e�B�b�NWeb���x����Z�p�ƌ����Ă��邪�AIoT�̗̈�ŗp�����邱�Ƃ͂��܂�Ȃ��B
3.2.2.8�@ �f�[�^�����ƕ��͋Z�p
IoT�ɂ���ē���ꂽ�f�[�^�ɑ��Ă͓K�ɏ������͂��s�����Ƃɂ���āA���܂��܂ȉ��߂⓴�@�A�X���邱�Ƃ��ł���B�����ł͈�ʓI�ȋZ�p������������B
�@ �f�[�^�}�C�j���O
�f�[�^�}�C�j���O�́A��ʂ̃f�[�^����p�^�[����W�������邽�߂̎�@�ł���B�W�߂�ꂽ�f�[�^�ɑ��āA�N���X�^�����O�A���ށA��A�A�ُ팟�o�ȂǓ��v�Z�p��AI�Z�p���K�p�����B
�A �N���X�^�����O
�������������f�[�^�|�C���g���O���[�v�������@�ŁA�f�[�^�̍\����W���𗝉�����̂ɖ𗧂B��\�I�Ȏ�@�ɂ́AK-means�@�A�K�w�I�N���X�^�����O�ADBSCAN�Ȃǂ�����B
�B �@�B�w�K
�@�B�w�K�́A�f�[�^����w�K���A�p�^�[����\�����f�����\�z����Z�p�ł���B���t����w�K�A���t�Ȃ��w�K�A�����w�K�Ȃǂ̃A�v���[�`������A���ݍł��i�����������̈�ƂȂ��Ă���B��\�I�Ȏ�@�Ƃ��āA��A���́A����A�����_���t�H���X�g�A�j���[�����l�b�g���[�N�Ȃǂ�����B
�C ���v���
���v��͂́A���v�I��@��p���ăf�[�^�Z�b�g�̓�����W���𗝉����邽�߂ɗp������B���ρA�W�����A���ցA��A�Ȃǂ̓��v�ʂ��g�p����A�W���I�ȉ�͋Z�p�̂ЂƂł���B
�D �r�b�O�f�[�^����
�r�b�O�f�[�^�����Z�p�͑�e�ʂ̃f�[�^�������I�ɏ������邽�߂̎�@�ŁA�N���E�h�R���s���[�e�B���O���s�����߂ɂ͕K�{�̋Z�p�ƂȂ��Ă���BHadoop�Ȃǂ̕��U�����t���[�����[�N���g�p�����B
�E ���A���^�C������
���A���^�C�������Z�p�́A�f�[�^���ɏ������ă��A���^�C���̓��@�邽�߂̎�@�ł��B���ɍ����ő�ʂ̃f�[�^�ɑ��u���ɔ����ł���悤�A�X�g���[�������A���G�C�x���g�����iCEP: Complex Event Processing�j�A���A���^�C�����͂Ȃǂ��p������B
3.2.2.9�@ �N���E�h�R���s���[�e�B���O�Z�p
�Z���T�œ���ꂽ�f�[�^�̓l�b�g���[�N����ďW��A�K�ȏ���/���͂��s���ĉ��������̂��ʏ�ł���B���̈�A�̏������s���v���b�g�t�H�[���͒ʏ�N���E�h�̒��Ŏ�������邱�Ƃ������B
�����̃v���b�g�t�H�[���Ƃ��Ă�2007�N�ɏo������Pachube������AIoT�̃A�[���A�_�v�^�ɂ悭�p����ꂽ�B2011�N�̓����{��k�Ђł�Pachube��p�������˔\�g�U��L���{�����ꂽ�B���T�[�r�X�͂��̌�2011�N��Xively�ɖ���ς�����A2018�N�ɂ�Google IoT �N���E�h�̈ꕔ�ƂȂ����B
���݂ł͑��̃N���E�h�v���b�g�t�H�[��(AWS, Google, Azure�Ȃ�)�͂������IoT�����̃T�[�r�X���܂Ƃ߂Ē��Ă���B�����ł�AWS(Amazon Web Services)���ɂƂ���IoT�����̃N���E�h�R���s���[�e�B���O�T�[�r�X�ɐG���B
�@ �N���E�h�v���b�g�t�H�[��
AWS IoT�́AIoT�f�o�C�X����̃f�[�^�����W���A�f�o�C�X�̊Ǘ���A���^�C�����́A�\�����͂Ȃǂ̋@�\����Ă���B
�A �N���E�h�X�g���[�W
Amazon S3�́A�N���E�h�X�g���[�W�Ƃ��đ�e�ʂ̃f�[�^��ۑ����A�K�v�Ȏ��ɃA�N�Z�X�\�ł���B
�B �N���E�h�f�[�^�x�[�X
Amazon DynamoDB�͑�K�͂ȃN���E�h�f�[�^�x�[�X�ŁA��K�͂ȃf�[�^�Z�b�g���Ǘ����A�����ŃX�P�[���u���ȃf�[�^���������s����B
�C �N���E�h�R���s���[�e�B���O
Amazon EC2�́A���z�T�[�o���N���E�h��œ��I�Ɋ��蓖�āAIoT�f�o�C�X����̃f�[�^�̏������x������N���E�h�R���s���[�e�B���O�T�[�r�X�ł���B�����\�͂��_��Ɋ��蓖�Ă邱�Ƃ��ł���B
�D �T�[�o�[���X�R���s���[�e�B���O
AWS Lambda�́A�́A�K�v�ɉ����ăR�[�h�����s���A���\�[�X�̊Ǘ�������������T�[�o�[���X�R���s���[�e�B���O�T�[�r�X�ł���BIoT�Z���T�Ȃǂ���̃g���K���x�[�X�Ƃ����C�x���g�h���u���ȃR���s���[�e�B���O���e�ՂɎ����\�ł���B
3.2.3�@ IoT�̑�\�I�ȃT�[�r�X��
�{�͂ł́AIoT�̑�\�I�ȃT�[�r�X����������B
3.2.3.1�@ �X�}�[�g�z�[��
�ƒ���̗l�X�ȃf�o�C�X�i�Ɩ��A�Z���T�A�Ɠd�Ȃǁj�����o�C���A�v���≹���A�V�X�^���g�ɂ���āA���u����f�o�C�X�𐧌䂵����A�����������肷�邱�Ƃ��s���B�Ɠd�����Ɩ�����A�G�A�R���̐���ɂ�鉷�x�Ǘ��A�Z�L�����e�B�J�����A�X�}�[�g���b�N�A�G�l���M�[�Ǘ��V�X�e���Ȃǂ��܂܂��B2022�N�ɂ̓A�}�]���A�O�[�O���A�A�b�v���Ȃǂ����S�ƂȂ����X�}�[�g�z�[���̂��߂̋��ʋK�iMatter�i�}�^�[�A�ȉ��}�^�[�j�������[�X����A����ɏ������邱�ƂŁA���l�ȉƓd�̐���Ǘ����\�ɂȂ낤�Ƃ��Ă���B
3.2.3.2�@ �X�}�[�g�V�e�B
������ʃV�X�e���̊Ď��A�S�~���̃t����Ԃ̃��j�^�����O�A���H��ʂ̗���̍œK���A�����Ɩ��̐���ȂǁA�s�s�C���t���̌���������P�Ɋ��p���ꂦ��B
3.2.3.3�@ �_��
�y��Z���T�A�C�ۃZ���T�A���V�X�e���Ȃǂ̃f�o�C�X���g�p���āA�_�앨�̐�������j�^�����O���A���ʓI�Ȕ_�ƊǗ����s���B
3.2.3.4�@ �Y�Ɨp IoT
�����v���Z�X�̊Ď��ƍœK���A�@��̕ۑS�Ǘ��A�����`�F�[���̉����ȂǁA�H���q�ɂł̌�������Y������Ɋ��p�����B
3.2.3.5�@ �w���X�P�A
�g�ɂ���f�o�C�X�i�E�F�A���u���j��Z���T��p���āA�l�̌��N��Ԃ����A���^�C���Ń��j�^�����O���A��Ë@�ւ���҂Ƌ��L����B
3.2.3.6�@ ���r���e�B
�����^�]�Ԃ̊J����A�ԗ��̃����[�g�Ď��A�^�]�f�[�^�̎��W�A��ʏ��̃��A���^�C���X�V�Ȃǂɗ��p�����B
3.2.3.7�@ ������
�ɊǗ��A�̔��f�[�^�̎��W�A�ڋq�s���̕��́A�X�}�[�g�V���b�s���O�̌��̒ȂǁA�����ƊE�ɂ������������ڋq�T�[�r�X����ɉ��p�����B
3.2.3.8�@ �G�l���M�[�Ǘ�
�X�}�[�g���[�^�[�̓����ɂ��d�͎g�p�ʂ̃��A���^�C���Ď���œK���A�Đ��\�G�l���M�[�̌����I�ȗ��p�Ȃǂ��܂܂��B
3.2.4�@ �����O�ɂ�����IoT���c��A�W�����@�ւȂ�
�{�͂ł́A�����O�ɂ�����IoT�Ɋ֘A�����W�����@�ւ�t�H�[�����A���c��ɂ��ĐG���B
3.2.4.1�@ ���ۓI��IoT�W�����g�D
�@ ITU-T SG20 https://www.itu.int/en/ITU-T/about/groups/Pages/sg20.aspx
�O���[�o���ȕW�����@�ւƂ��ẮA���ۋ@��ITU-T�̃O���[�v�̈�ł���ITU-T SG20 ����������BSG20�̓X�}�[�g�V�e�B�Ƃ��̒ʐM�Ɋւ���IoT�A�v���P�[�V�����ɏœ_�ĂČ������s���Ă���B
�A IEEE Internet of Things�iIoT�jTechnical Community https://iot.ieee.org/
IEEE�ɂ����ẮAIoT�S�ʂ̋Z�p�̔��W�A�W�����A����щ��p���T�|�[�g���邱�Ƃ�ړI�Ƃ��Ă���B
�B OneM2M https://www.onem2m.org/
OneM2M�́A2012�N�ɐݗ����ꂽ�قȂ�ƊE��IoT�f�o�C�X��A�v���P�[�V�����Ԃ̑��݉^�p���ƌ��������m�ۂ��邱�Ƃ�ړI�Ƃ����A�O���[�o���ȑg�D�ł���B�W�����A�Z�L�����e�B�A���݉^�p���̊m�ۂɊւ��Č�������Ă���B
3.2.4.2�@ �����ɂ�����IoT�֘A�g�D
�����ɂ����ẮAIoT��ړI�Ƃ��Ċe��̋��c���t�H�[�������ݗ����ꊈ�����s���Ă���B�����ł͎�ȑg�D���Љ��B
�@ �X�}�[�gIoT�t�H�[����<https://smartiot-forum.jp/about>
�X�}�[�gIoT�t�H�[�����́A2015�N10���ɐݗ�����AIoT���Ɋւ���A�Z�p�J���A�W�����A����уX�}�[�gIoT�\�����[�V�����̎��p�����x�����邽�߂ɁA�Y�ƊE�A�w�p�E�A���{�@�ւ����͂��Ċ������Ă���B
�A
�X�}�[�g�V�e�B�����A�g�v���b�g�t�H�[��
�@�@�@�@�@�@�@�@�@�@��https://www.mlit.go.jp/scpf/about/index.html>
���v���b�g�t�H�[���́A���{�@�ցA���Ԋ�ƁA�s���Ƃ̋��͂�ʂ��ăX�}�[�g�V�e�B�̊J���𑣐i���邽�߂̎��g�݂ł���B���̃v���b�g�t�H�[���́AIoT�₻�̑��̐�i�Z�p���g�p���āA���܂��܂ȓs�s�@�\��T�[�r�X�����A�������I�Ŏ����\�A�����ďZ�݂₷���s�s��n�����邱�Ƃ�ڎw���Ă���B�{�v���b�g�t�H�[���ɂ́A���t�{�A�����ȁA�o�ώY�ƏȁA���y��ʏȁA�f�W�^�����炪����A�˂Ă���B
�B �n��DX���i���{�^�n����IoT���i���{https://local-iot-lab.ipa.go.jp/
���{�ɂ�����n��DX���i���{��n����IoT���i���{�́A�f�W�^���g�����X�t�H�[���[�V�����iDX�j��IoT�Z�p�̒n��ւ̓����ƕ��y��ړI�Ƃ��Ċ������s���Ă���BIPA���劲�ł���B�{���{�́A���ɒn�������̂�n��o�ς̊������ɏœ_�āA��i�Z�p�����p���Ēn��ŗL�̉ۑ���������A�V���ȉ��l�n�o��ڎw���Ă���B
�C
�Z�L���A IoT �v���b�g�t�H�[�����c��
�@�@�@�@�@�@<https://www.secureiotplatform.org/about>
�����c��́AIoT�f�o�C�X��T�[�r�X�̃Z�L�����e�B���������A�M���ł���IoT���̍\�z��ڎw���c�̂ł���BIoT�̕��y�ɔ����Z�L�����e�B�̊m�ۂ͋ɂ߂ďd�v�ȉۑ�ł���A���c��́A�Z�L�����e�B���X�N�ɑΏ����A���S��IoT�G�R�V�X�e���𐄐i���邱�Ƃ�ړI�Ƃ��Ă���B
�D
IoT�T�[�r�X�A�g���c��
�@�@�@�@�@�@�@<https://www.aiots.org/about/establishment/>
IoT�T�[�r�X�A�g���c��́A�قȂ�IoT�T�[�r�X��v���b�g�t�H�[���Ԃ̘A�g�𑣐i���A���ꂳ�ꂽIoT�G�R�V�X�e���̍\�z��ڎw���c�̂ł���B���̋��c��̎�ȖړI�́A�@���v���b�g�t�H�[���̑��݊����E���݉^�p�������コ���邱�Ƃɂ���B
3.2.5�@ IoT�̃r�W�l�X���Ƃ���ɂƂ��Ȃ��ۑ�
3.2.5.1�@ IoT�̃r�W�l�X�̈�
3.�ł͊e���IoT�T�[�r�X�ɂ��ĐG�ꂽ�������ł͂����̃r�W�l�X���Ƃ���ɂƂ��Ȃ��ۑ�ɂ��ďq�ׂ�
�r�W�l�X�̈�ł�B2B��B2C�̗�����ɂ�����IoT�r�W�l�X�̎��g�݂����{����Ă���B
B2B�̈�ł͐�̃X�}�[�gIoT�t�H�[�����ɑ����̎��Ⴊ�f�ڂ���Ă���ʂ�A�����Ƃ��\��Ƃ��āA���Y���C���̍œK����@�B�̉��u�Ď��A�\�h�ۑS�A�G�l���M�[�Ǘ��A�T�v���C�`�F�[���̌������Ȃǂ��s���Ă���B�܂��A�����ƂɌ��炸�����A�_�ƁA���݂ȂǑ��̎Y�Ƃł������ȗ��p�̋@�^������B
���B2C�̈�ł̓X�}�[�g�z�[���f�o�C�X�A�E�F�A���u���Z�p�A���N�Ǘ��A�v���P�[�V�����ȂǁA����Ҍ�����IoT���i�̕��y���n�܂��Ă���B�܂��A�����ԋƊE�ɂ�����i�r�Q�[�V������ԗ��Ǘ����s���R�l�N�e�b�h�J�[���A��ʏ���Ҍ���IoT�Z�p�Ƃ��ďd�v�ł���B
�r�W�l�X���́A�s��̃j�[�Y��ƊE�̐��n�x�ɂ���Ĉق�BB2B�\�����[�V�����́A�R�X�g�팸���������}��ړI�ŁA��r�I��������i��ł������A����҂ɒ��ڊւ��B2C�Ɋւ��ẮA��w�̏���҂̎���̈ӎ��g�傪���҂����B
���{�ł́A�X�}�[�g�V�e�B��Љ�ۑ�̉�����ڎw�����v���W�F�N�g�A�܂����[�J��5G�̗��p���i�ȂǁA���{����̐ϋɓI�Ȏx���������AB2B�����B2C�̗�����IoT�̃r�W�l�X�����i�݂���ƌ����悤�B
3.2.5.2�@ ���E�ɂ�������{��IoT�r�W�l�X
���E�I�Ɍ����Ƃ����{��IoT�r�W�l�X�̌���͂ǂ̂悤�ɂȂ��Ă���̂��낤���H
�} 3‑42�́A������ �gIoT���ۋ����͎w�W -2021�N���� [�T�v]- ���甲������IoT�s��̍��E�n��ʃV�F�A�Ɛ����������������̂ł���B���������ƁAIoT�s��S�̂ł͒����̃V�F�A���ł������A�č��Ɠ��{�������ł��邪���{�̃V�F�A��2016�N����2021�N�ɂ���

�} 3‑42�@IoT�s��̍��E�n��ʎЂƐ������i������ �gIoT���ۋ����͎w�W -2021�N���� [�T�v]- �j���甲���h
��27%����17%�ɂ܂ʼn��~���Ă��邱�Ƃ��킩��B���E�I�ɂ�IoT�s��͐����𑱂������A���{�̋����͂͑��ΓI�ɒቺ���Ă��邱�Ƃ��킩��B���̌����͂����炭����20�N����ICT���������E�̑����ɔ�ׂē��{�������x��Ă����̂ƒʂ���_�ɂ���̂ł͂Ȃ����낤���H
�����ɋL�����Ƃ��A���{��DX���̒x��AICT�ւ̓����͒P�Ȃ�������E�ȗ͉���ړI�Ƃ����P�[�X�������A�V���ȃr�W�l�X�𗧂��グ��悤�ȐV���l�n���ɂȂ����Ă��Ȃ��Ƃ̎w�E�����邪�A�����ɂ����Ă͂܂邩�Ǝv����BIoT�ɂ��V�r�W�l�X�n�o�����҂����B
���{�ŃO���[�o�������ꂽIoT�r�W�l�X��j�Q���Ă��錴���̂ЂƂɃO���[�o���ȕW������i�߂�\�͂Ɍ����Ă���_���������悤�B����o���A�������ɂǂ����Ă��I�[���W���p���Ƃ��ē������[�����^��������A�N���X�{�[�_�ŕW�����A�Ђ��Ă̓r�W�l�X����������Ƃ���܂ōs���ĂȂ���������B
3.2.5.3�@ �P�[�u���e���r�ƊE�ɂ�����IoT
�T�_
�G���h���[�U�̉ƒ�ڌڋq�Ƃ��Ċm�ۂ��Ă���P�[�u���e���r���Ǝ҂́AIoT�����p���ėl�X�ȕ���ŐV���ȃT�[�r�X��r�W�l�X���f���̍\�z��ڎw���͔̂��ɖ]�܂������Ƃł���B�P�[�u��TV���Ǝ҂́A�G���h���[�U�ւ̃��[�`�ɉ����āA�n��ڋq�u���̃X���[���N���E�h�I�ȋ@�\�����邱�Ƃł������̃T�[�r�X�̉\�����J������Ǝv����B

�} 3‑43�@�P�[�u�����Ǝ҂�IoT�T�[�r�X����������ۂ�SWOT��
��ʓI�ł͂��邪�A���{�̃P�[�u��TV��Ђ�IoT�r�W�l�X����������ɍۂ��Ă�SWOT�������Ă݂��B�����} 3‑43�Ɏ����B���݂͊��ɑ����̉ƒ�Ƀ��[�`���Ă���l�b�g���[�N��ՂȂ�тɑш��L���Ă��邱�ƂŁA���R���e���c�z�M���\�ȋ@�\�����ɂ���_�ł���B�����݂͋ƊE�ł̌X�̎Ђ̋K�͂����������߁A�v������������S���I�ȃX�y�b�N���ꂪ�e�Ղł͂Ȃ��_���������悤�B�@��Ƃ��Ă͒n��S�̂��J�o�[���Ă���̂ŁA��������ėႦ�Βn��S�̂��J�o�[����悤�Ȗh�Ƃ�A���R�ЊQ�Ď��Ȃǂ����������L���ɂȂ�Ǝv����B�Ō�Ɏ�_��������Ƃ���A�n����J�o�[���Ă��邪�̂ɁA�����C���V�f���g�����������ۂɂ͂��̉e�����n��S�̂ɋy�т���_��������Ȃ��B
3.2.5.4�@ 6.2 �P�[�u�����Ǝ҂ɂ��IoT�T�[�r�X
������āA���ɐ��X�̃P�[�u��TV�ł̓T�[�r�X���s���Ă��邪�A��\�I�ȃr�W�l�X�Ƃ��Ă͎��̂悤�ȍ��ڂ���Ƃ��ċ������悤�B
���̓X�}�[�g�z�[���T�[�r�X�ł���B��ɏq�ׂ��X�}�[�g�z�[���f�o�C�X��l�b�g���[�N�ڑ����ꂽ�Ɠd����A�ڋq�̉ƒ���X�}�[�g�z�[�������邽�߂̃T�[�r�X�̓W�J�ł���B
���̌��Ƃ��ẮA�Z�L�����e�B�T�[�r�X�̒ł��낤�B �P�[�u��TV���Ǝ҂��Z�L�����e�B�J������z�[���Z�L�����e�B�V�X�e������AIoT�Z�p�����p���Čڋq�̉ƒ��r�W�l�X�̃Z�L�����e�B�����コ����T�[�r�X�̓W�J�����蓾�悤�B�P�[�u��TV���Ǝ҂̏ꍇ�A�n��ɖʓI�ɓW�J���邱�Ƃ��\�Ȃ̂ŁA�ʌڋq�̃Z�L�����e�B�݂̂Ȃ炸�G���A�Ƃ��ẴZ�L�����e�B�����@���������`�����X������Ǝv����B
����Ɍ��ƂȂ�̂͒n��S�̂ŊǗ��\�ȃG�l���M�[�Ǘ��T�[�r�X����������B �P�[�u��TV���Ǝ҂��G�l���M�[���j�^�����O�V�X�e����X�}�[�g���[�^�[����A�ڋq�̃G�l���M�[�g�p�ʂ��Ď����A�ߖ����������x������T�[�r�X��W�J����T�[�r�X���l������B���̏ꍇ�A�n��Ƃ��Ă̋C����d�͋����̓x���������v�炢�A�œK�Ȑ�����g�[�^���ŕ]��������A�e�ƒ��I�t�B�X�ւ̐�����s���V�i���I���l������B�����B2C�ւ̓K�p�ł������AB2B�Ƃ��ẴG�l���M�[�}�l�[�W�����g�ł���Ƃ�������B
3.2.6�@ IoT�̓W�]
�{�͂ł́A���܌��J�I�Ȃ���A�����IoT�ɂƂ��đ傫�����W�𐋂����|����ɂȂ肻���ȍ��ڂɂ��Đ����������B
3.2.6.1�@ AI��IoT
�^���]�n���Ȃ��AAI��IoT�f�o�C�X����������c��ȃf�[�^����Ӗ��̂��铴�@�𒊏o���A�X�}�[�g�Ȉӎv������T�|�[�g���邱�ƂŁAIoT�̉\����傫���L���悤�B����IoT�ł�xx�����o�������A�Ƃ������悤�Ȓ�^�I�ȗv�����������߁A�@�B�w�K�ɂ���Đl�Ԃ��ւ�邱�ƂȂ��A�܂�������f�����N���s�v�ŕK�v�ȏ������s����\��������B�ł���@�\��Ƃ��ẮA
• ���A���^�C���f�[�^����: �Z���T����̃��A���^�C���f�[�^��v���ɕ��͂��A�����̃t�B�[�h�o�b�N��A�N�V���������{����B
• �p�^�[���F��: �@�B�w�K�������邱�ƂŁA�擾�f�[�^�̒�����p�^�[����F�����A�ُ팟�m��\�����͂����{�B
• �\���ێ�: �̏�\����@��̃����e�i���X���K�v�ȃ^�C�~���O��\�����A�_�E���^�C���������B
• �p�[�\�i���C�[�[�V����: ���[�U�̏K����D�݂��w�K���A�J�X�^�}�C�Y���ꂽ���[�U�[�G�N�X�y���G���X�����B
• �Z�L�����e�B�Ď�: �ُ�ȃl�b�g���[�N�g���t�B�b�N��s�R�ȍs�������o���āA�Z�L�����e�B�N�Q��h�����߂̑����x���V�X�e�������B
�@�B�w�K��IoT�̑g�ݍ��킹�́A�P�Ƀf�[�^�����W���邾���łȂ��A���̃f�[�^�����p���ĐV���ȉ��l��n��������B
3.2.6.2�@ �G�b�W�R���s���[�e�B���O
�@IoT�ɂ�����G�b�W�R���s���[�e�B���O�́A�f�[�^���W���f�[�^�Z���^�[��N���E�h�ł͂Ȃ��A�f�[�^�̔������ɋ߂��u�G�b�W�v�A�T�^�I�ɂ͌��n�Ńf�[�^���W��m�[�h�ŏ�������A�v���[�`�ł���B����ɂ��A�������Ԃ̒Z�k�A�ʐM�ш敝�̐ߖ�A�v���C�o�V�ƃZ�L�����e�B�̌��オ�\�ƂȂ�B���̓����Ƃ��āA���M�ɂ����鎞�Ԃ��ȗ����A���A���^�C���ɋ߂��������\�ɂ����x�����A�K�v�܂��͏d�v�ȃf�[�^�݂̂��G�b�W�őI�����đ��M���邱�Ƃɂ��l�b�g���[�N�̑ш�ߖ�A�s�v�ȃ��[�U�f�[�^�̓t�B���^���đ���Ȃ����Ƃɂ��v���C�o�V�[�ƃZ�L�����e�B�̊m�ہA���Ƀl�b�g���[�N����Q�ƂȂ��Ă����[�J���œ���p�������錘�S���Ȃǂ������b�g�Ƃ��ċ�������B
�G�b�W�R���s���[�e�B���O�́A�����^�]�ԁA�X�}�[�g�t�@�N�g���[�A�s�s�C���t���Ǘ��A�H����̐��Y���Ǘ��ȂǁA�x����������Ȃ����ł�IoT�A�v���P�[�V�����ɓ��ɏd�v�ł���B
3.2.7�@ Federated Learning�i�A���w�K�j
���Ƀf�o�C�X�����U�z�u�����P�[�X������IoT�\�����[�V�����Œ��ڂ����@�B�w�K�Z�p�̂ЂƂ�Federated Learning�ł��낤�A�f�[�^�̃v���C�o�V�[��ی삵�Ȃ���@�B�w�K���f�����g���[�j���O���邽�߂̃A�v���[�`�ŁA2017�NGoogle�ɂ���Ē�Ă��ꂽ�B�Ⴆ�Όl�l�̃X�}�[�g�z���̕������͂ɂ��āA�S�Ă̓��͂��N���E�h�ɏW�߂��X�̃X�}�[�g�z���ŕ��U�w�K�������ʂ݂̂��A�b�v���[�h���Ė߂����ƂŌl�f�[�^�̃v���C�o�V�����A�w�K�����{�ł��邽�߁A������ɁA��ÁA���Z�A�X�}�[�g�V�e�B�ȂǁA�f�[�^�̋@���������ɏd�v��IoT�A�v���P�[�V�����ŘA���w�K�͏d�v�ɂȂ�ƍl������B
3.2.8�@ FIWARE
FIWARE�́A���[���b�p�Ŏn�܂����C�j�V�A�e�B�u�ŁA�W�������ꂽ�X�}�[�g�\�����[�V�����̊J���̂��߂̃v���b�g�t�H�[���ł���B�X�}�[�g�V�e�B�A�X�}�[�g�C���_�X�g���[�A�X�}�[�g�A�O���J���`���[�ȂǁA���܂��܂ȕ���̃f�W�^���ϊv���x�����邽�߂�API��f�[�^���f������`�������Ă���B
FIWARE�̎�v�ȃR���|�[�l���g�Ƃ��ẮA�f�o�C�X��Z���T����̏����W�A�f�[�^�����A���^�C���ŏ�������I���I���R���e�L�X�g�u���[�J�[�A�قȂ�IoT�v���g�R���ƃR���e�L�X�g�u���[�J�[�Ƃ̊Ԃŏ���ϊ�����IoT�G�[�W�F���g�A�A�v���P�[�V�������e�ՂɃf�[�^�ɃA�N�Z�X�ł��邽�߂̃f�[�^/�R���e�L�X�gAPI�A�A�v���P�[�V�����Ԃŋ��ʂ̗����𑣐i���邽�߂̕W�������ꂽ�f�[�^���f������������B
�@FIWARE�͓��ɁA���݉^�p���̖����������邱�Ƃɏœ_�āA�R���e�L�X�g�������ɕ\���ł���X�L�[��������Ă���B���̂��ߌ����̃C���t���Ǘ��A��ʊǗ��A�G�l���M�[�Ǘ��ȂǑ���ɂ킽��p�r�ɓK�p����Ă���B����ŁA�L�@���I���g���W�I�ł���̂ŁA�p������L���̈�Ō�b�̍��v���K�v���Ǝv����B
3.2.9�@ ������
IoT�́A���ꂩ����{�ɂƂ��ĊԈႢ�̂Ȃ��ۑ�ƂȂ鏭�q����A�h�ЁE���Б�A�C���t���ێ��A�l�X�̌��N�ێ��A�e��Y�Ƃ̔��W�ɂƂ��ăG�b�Z���V�����Ȗ������ʂ������ƂɂȂ�B�������A���̑��x�͌����Ĉ�C�ɐi�ނ킯�ł͂Ȃ��A�������̃g���C�A���̃x�X�g�v���N�e�B�X�̒�����B2B�̃r�W�l�X�����܂�A����҂������̃f�o�C�X�ɐG��A���̗�������������A�����ē�����O�̓���̃R���f�B�e�B�ƂȂ�Ƃ���B2C�̃r�W�l�X���������W���Ă䂭�ł��낤�B
�@�n�߂͕��y���͂��������Ȃ���������Ō��݂͍L�����y���Ă����Ƃ���IPv6������B2000�N�����ɓ��{��IPv6�Z�p�ɏG�łĂ���ƌ����Ȃ���A���y�͑S���i��ł��Ȃ������B�������Ȃ���IPv4���͊����A�A�b�v����}�C�N���\�t�g�AGoogle�炪��������IPv6�̃T�|�[�g/�ڍs��i�߂�ƁA�����Ƃ����Ԃɐ��E�ɂƂ��ē�����O�̑��݂ɂȂ����BIoT���܂����y���Ȃ����Ȃ��A�ƌ����Ȃ���A���̂܂ɂ��C��������g�̉��ɂ����ē�����O�ŒN�������s�v�c�Ǝv��Ȃ����E�ɂȂ��Ă���ƕM�҂͑z������B
3.3�@ �V�����f���T�[�r�X�^�Z�p�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@
3.3.1�@ XR
3.3.1.1�@ XR�̖���
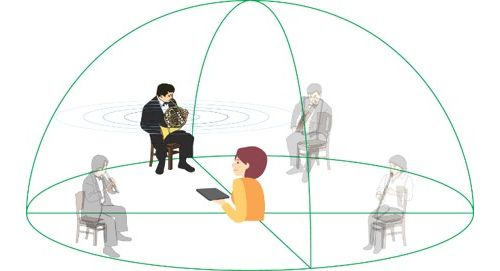
Society 5.0�̎����Ɍ����āA�t�B�W�J����ԂƃT�C�o�[��Ԃ���̉�����\�z�ł���CPS�i�T�C�o�[�E�t�B�W�J���E�V�X�e���j���f�����Ă���B���̍\�z��������邽�߂̋Z�p�̂ЂƂ�XR�ł���BXR�́AVR (Virtual Reality) ��AR (Augmented Reality) �AMR (Mixed Reality) �ȂǁA�T�C�o�[��Ԃƃt�B�W�J����Ԃ�Z�����������ʂ�l�Ԃ̒m�o�Ƀt�B�[�h�o�b�N����Z�p�̑��̂ł���B�T�C�o�[��Ԃɂ�����AI�Ȃǂŕ��͂������ʂ��A�t�B�W�J����Ԃɓ`�B���邱�ƂŁA�l�̍s���Ȃǂ�ϗe�����������S���BXR�Z�p�����p�����R���e���c�́A�܊����~�b�N�X���ꂽ����܂łɂȂ��Տꊴ���̌����A�����鐶���V�[���̒��őn�o���邱�Ƃ��ł���B
3.3.1.2�@ XR���ڎw���p
2030�N�ɂ́A������ꏊ�ɐݒu���ꂽIoT�f�o�C�X��Z���T�ɂ��A�t�B�W�J����Ԃ̏��̓X�L��������A�T�C�o�[��ԏ�Ńt�B�W�J����Ԃ��Č��ł���悤�ɂȂ�A�����ɉˋ�̕��i��m�܂ŏd�ˍ��킹��悤�Ȋg������������邱�Ƃ����҂����B
�����́A�T�C�o�[��ԏ�ō\�z���ꂽ���E�ł��郁�^�o�[�X�Ȃǂ̃v���b�g�t�H�[�������XR�Z�p�ɂ�胆�[�U�ɒ����B���o�I�ɂ́A���ʓI�ȉf���\���ɗ��܂炸�AVR�^AR�O���X�ł̒͂������A���̉f����\������z���O���t�B�ɂ������ƌ��������t���Ȃ����̕\�������������B�܂��A��̍L����܂ł��������闧�̉�����m�ɐG�ꂽ���o����t�H�[�X�t�B�[�h�o�b�N�Ȃǂ̗l�X�Ȓm�o�\����g�ݍ��킹�Č܊��ɓ`�B����}���`���[�_���A�g�����������B����ɂ́A�T�C�o�[��Ԃƃt�B�W�J����Ԃ��Ȃ��A�����̖c��ȃf�[�^���u���Ɏn�����\�ȍ������`�������������B
��������XR�Z�p�̐i�����R�~���j�P�[�V�����X�^�C���ɑ���ȕϊv�������炷�B��̓I�ɂ́A�����̕����ɂ��Ȃ���A�ߋ��ɖK�ꂽ�ꏊ���Č����A���̎v���o�����u�̉Ƒ���F�l�Ƌ��L����B�e�����l�̌��ɐG��A�����Ǝ���d�˂�B����Ȍ��t�����ł͓`���Ȃ��@�ׂȃj���A���X�̕\���܂ł��\�Ƃ���B
�t�B�W�J����Ԃ��Z���V���O�������̓T�C�o�[��ԂŊg������A�܊��ɓ���������XR�R���e���c�Ƃ��āA�������Ƀf�[�^���k���ꂽ�`�ŁA�^�C�����O�����������邱�ƂȂ��݂��̋�Ԃ��s��������B���̌��ʁACPS�ɂ����ăV�[�����X��XR�̌��������炷�B
3.3.1.3�@ ���̒��̓���
COVID-19�̊����g��ɔ��������[�g���[�N��o�[�`�����C�x���g�̋}���ȕ��y�ɔ����A���^�o�[�X�𒆐S�Ƃ��āAXR�Z�p�����p�������u�ł̃R�~���j�P�[�V������R���{���[�V����������ʓI�ƂȂ����B�G���^�[�e�C�������g����r�W�l�X�̗̈�܂ŕ��L���p�r�Ŋ��p����Ă���B�G���^�[�e�C�������g�̗̈�ɂ����ẮA�I�����C���łȂ������Q���҂ƈꏏ�ɗV�Ԃ��Ƃ��\�ȃQ�[���A���y�p�t�H�[�}���X�Ȃǂ̃C�x���g�ӏ܁A�o�[�`�������[�����ł̃V���b�s���O�Ƃ��������[�X�P�[�X���l������B�r�W�l�X�̗̈�ɂ����ẮA3D��ԓ��ł̌��C�E�g���[�j���O�Ȃǂ̋����A�Q���ғ��m�ŏ�����L���Ȃ���f�B�X�J�b�V�������s����c��ړI�Ƃ������p���l������B
���ۂɁAVR�O���X����������̌��ƁA�A�o�^�[�ɂ�鎩�ȕ\������g�����o�[�`������c��W��������Ă��Ă���[1]�B���l�̋Z�p�����p���āA�o�[�`�����L�����p�X��o�[�`�����I�t�B�X��{�i��������č��̑�w���Ƃ��o�ꂵ�Ă���[2][3]�B�����f�o�C�X�̐i�����i��ł���AVR�^AR�O���X�Ɋւ��āA�č��⒆���Ȃǂ̑��IT��Ƃ𒆐S�ɍ��掿�E�L����p�E���^�E�y�ʂƂ��������\���オ�����ɐi�߂��Ă���A���p�V�[�����g�債�Ă���B
���̂悤�ɁAXR�Z�p�̕��y�͒����ɐi��ł�����̂́A�]���͓���̏��i�E�T�[�r�X�݂̂��f�W�^��������A�T�C�o�[��Ԃ̃t�B�[�h�o�b�N������̌��͒f�ГI�Ȃ��̂ɗ��܂��Ă����B
�����ŁA�G���^�[�e�C�������g�̗̈�ɂ����郆�[�X�P�[�X�̈��Ƃ��āAKDDI�����\�����o�[�`�����a�J���Љ��B���̃o�[�`�����a�J�ł́A�T�C�o�[��ԓ��ł͏a�J�̊X���݂��f�W�^���c�C���Ƃ��čČ�����A24���ԁA���E���ǂ�����ł��A���g���A�o�^�[�ƂȂ��ĎQ�����邱�Ƃ��\�ł���[4]�B�܂��A�a�J��ɂ����ẮA�X�}�[�g�t�H����X�}�[�g�O���X�ɓ��ڂ��ꂽ�J�����z���̉f�������Ԃ�F������VPS (Visual Positioning Service)�����p���āA���ۂ̏a�J�̌i�F�Ɉ��H�X���Ȃǂ�AR�ŕ\�������T�[�r�X�̎��؎������s��ꂽ�i�} 3‑44�j[5]�B

�} 3‑44�@�a�J�X�N�����u�������_�ɂ�������؎����ł̑̌��C���[�W
3.3.1.4�@ �ۑ�
���̂悤�ɁAXR�Z�p�����p�����V�̌��̑n�o����͏��X�ɏo�Ă��Ă��邪�A�X�Ȃ郆�[�X�P�[�X�̊g���[���ɂ����Ă͉������ׂ��ۑ������B�����ł́A�{�e�ŏЉ�郁�^�o�[�X�A�_�Q�f�[�^��z���O���t�B�Ȃǂ̗��̕\���̊ϓ_�ł̉ۑ�ɂ��ďq�ׂ�B
�܂����^�o�[�X�Ɋւ���ۑ�ɂ��ďq�ׂ�B���^�o�[�X�ł́A�������ꂽ�l�Ɠ�����Ԃ����L���Ȃ���A�����̕��g�Ƃ��ẴA�o�^�[����ăR�~���j�P�[�V�����Ȃǂ��s�����Ƃ��\�ł���B�} 3‑45�̓��^�o�[�X���ŕ\��������Ԃ�A�o�^�[�̃C���[�W�ł��邪�A������CG�iComputer Graphics�j�ŕ\�������[6]�B���[�X�P�[�X�ɂ���ẮA��������蒉���ɍČ����邱�Ƃ����߂���B���o�̊ϓ_�ł́A�Ⴆ�A���^�o�[�X���ł̃V���b�s���O��X�|�[�c�ϐ�Ȃǂ�z�肷��ƁA�l����ߕ��Ȃǂ̎����܂ōČ�����邱�Ƃ����҂����B
�} 3‑45�@���^�o�[�X��ɍ\�z���ꂽ��ԂƃA�o�^�[�ɂ��\��
�܂��A�} 3‑46�̓��^�o�[�X���ŕ\������鉹���\���̃C���[�W�ł���[7]�B���^�o�[�X���̃��[�U��I�u�W�F�N�g�̈ʒu������Ȃǂɂ���āA���̕���������ω������闧�̉����̕\��������B���̉����́A�V�A�^�[�ӏܗp�r�ł́A�}���`�`�����l���̃T���E���h�I�[�f�B�I�V�X�e���𗘗p���Ă��Տꊴ�̍����\�����\�ƂȂ��Ă��Ă���[8]�B����ŁA���^�o�[�X�Ȃǂł̗��p�ɂ����ẮA�X�}�[�g�t�H���̃X�s�[�J�[��w�b�h�t�H���Ȃǂɂ��X�e���I�Đ�����ʓI�ł���B�X�e���I�Đ��ɂ����闧�̉����̕\�����s���A�v���[�`����������Ă���[9]�B���^�o�[�X���ł̉��y���t��R�~���j�P�[�V�����Ȃǂ�z�肷��ƁA�����̐l�����t������A���b�����肷��ۂ́A��ԓ��̉��̍L�����͋[�ł��邱�Ƃ����҂����B
�} 3‑46�@���^�o�[�X���ł̉����\���̃C���[�W
�G�o�ɂ����Ă��A���^�o�[�X���̐l��I�u�W�F�N�g�ɐG�ꂽ�ۂ̊��o��ł��邱�Ƃ��]�܂����B�Q�[���̃R���g���[���[��O���[�u�^�̃f�o�C�X�Ȃǂ�����U���ɂ��t�B�[�h�o�b�N�Ȃǂ���������Ă��邪[10][11]�A���[�X�P�[�X�ɓK�����f�o�C�X�ɂ����āA��y�ɑ@�ׂȃt�B�[�h�o�b�N���s���邱�Ƃ͗L�p�ł���ƍl������B���̑��A�k�o�□�o�̍Č��ɂ��ẮA�G��I�Ȏ��Ⴊ�������o�Ă����i�K�ł͂��邪�A���^�o�[�X���̗Տꊴ�̂���̌�������Ɍ㉟������t�B�[�h�o�b�N�����҂����[12][13]�B
���ɗ��̕\���Ɋւ���ۑ�ɂ��ďq�ׂ�B�]���̃T�C�o�[��Ԃ���̎��o�I�ȃt�B�[�h�o�b�N�̌��́A���2D�f�B�X�v���C�����`�Ԃɐ�������Ă������A3D�Ɋg�����邱�ƂŁA�} 3‑47�̂悤�Ȃ��Տꊴ�̂���̌��������ł���ƍl������B

�} 3‑47�@���̕\�������p�������o�I�ȃt�B�[�h�o�b�N�̃C���[�W
3D�f���̃f�[�^�\���`���Ƃ��āA��Ԃɂ��镨�̂�_�̏W���Ƃ��ĕ\������_�Q������B�_�Q�͋�Ԃ�_�̈ʒu�Ƃ��̐F�ŕ\������V���v���ȃf�[�^�\���ł���A�l�X�ȃ��[�X�P�[�X�ŗ��p�����B����ŁA3D���������߁A���̃f�[�^�ʂ͖c��ƂȂ�B���̂��߁A�_�Q�f�[�^�����k����Z�p�͕K�v�s���ƌ�����ł��낤�B3D�R���e���c�̕��y�ƂƂ��ɁA�l�b�g���[�N�ɗ��ʂ���f�[�^�ʂ͍���v�X���傷��ƍl�����邽�߁A�X�Ȃ鍂�����Ȉ��k�����߂���B
�܂��A3D�f���̕\���Z�p�Ƃ��āA���ߌ^�f�B�X�v���C��n�[�t�~���[�Ȃǂɂ����3D��Ԓ���2D�̍��掿CG�𓊉e����A�v���[�`����������Ă���[14]�B����ŁA�����ƌ������邱�Ƃ������I�ɕs�\�ȉf���\�����������ׂ��A�����̂̕\�ʂ��甽�˂��ē�������g���L�^�E�Đ�����z���O���t�B�����p�������̕\���f�B�X�v���C�Z�p[15]�̌����J�����i�߂��Ă��邪�A�\���p�f�o�C�X�Ȃǂ̐���A���掿�E�L����p�̉f���\���͎�������Ă��Ȃ��ł���B
���̂悤�ȏ̒��ŁA�X�Ȃ郆�[�X�P�[�X�̒T����ۑ�����Ɍ��������g�݂��o�Ă��Ă���B���߈ȍ~�ɂ����āAXR���ڎw�����E����������\���v�f�Ƃ��āA���^�o�[�X�A�_�Q�f�[�^�A�z���O���t�B�ɏœ_�����ĂāA���ꂼ��̏ڍׂɂ��ďq�ׂ�B
3.3.2�@ ���^�o�[�X
3.3.2.1�@ ���^�o�[�X�̓���
�܂����^�o�[�X�̓����ɂ��ďq�ׂ�B���^�o�[�X�ɂ��ẮA���m�Ȓ�`�͂Ȃ����A���[�U�ԂŃR�~���j�P�[�V�������\�ȁA�C���^�[�l�b�g���̃l�b�g���[�N��ʂ��ăA�N�Z�X�ł���A���z�I�ȃf�W�^����Ԃƌ����Ă���[16]�B
��q�̂悤�ȑ̌������T�[�r�X���������Љ��B���E�ő勉�̃��^�o�[�X�Ƃ��āAVRChat [17]�ƌĂ��T�[�r�X������Ă���A���E������Q�����郆�[�U�ƃA�o�^�[�������b��C�x���g�ւ̎Q���Ȃǂ��y���ނ��Ƃ��ł���B�܂��AEpic Games�Ђ�����Fortnite [18]�Ȃǂ̂悤�ɁA�Q�[���@�\���������킹���T�[�r�X�����݂���BFortnite�ł́A���[�U����Ԃ��f�U�C�����邱�Ƃ��ł��A���̋�Ԃ𑼂̃��[�U�ƈꏏ�Ɋy���ނ��Ƃ��\�ł���B�܂��A�r�W�l�X�����̃R���{���[�V�����c�[���Ƃ��āAMicrosoft Mesh�Ȃǂ�����Ă���[19]�B�܂��AMeta�Ђ̓��^�o�[�X�T�[�r�X�̒ɉ����āA���v�����̍����̌����\�Ƃ��邽�߂�XR�f�o�C�X�̊J������s���Ă���[20]�B���{���̃��^�o�[�X�Ƃ��ẮA�N���X�^�[�Ђ̃��^�o�[�X�v���b�g�t�H�[���ł���cluster[21]������Ă���A�X�}�[�g�t�H���APC�AVR�w�b�h�Z�b�g�Ȃǂ̑��l�ȃf�o�C�X����Q�����邱�Ƃ��ł���B�܂��A���݂���s�s���Č�������ԓ����U��ł���s�s�A���^���^�o�[�X�ł���KDDI�炪���i����o�[�`�����a�J�Ȃǂ�����Ă���[4]�B
���̂悤�ɁA���^�o�[�X�Ƃ��ėl�X�ȃT�[�r�X������Ă��邪�A����������ɍ��x��������g�݂��o�Ă��Ă���B�����ł́A���^�o�[�X�̐i���Ɍ��������g�݂̈��Ƃ��āA�A�o�^�[�̃t�H�g���A���\���ƃ}���`���[�_���A�g�ɂ��ďЉ��B
3.3.2.2�@ ���^�o�[�X��i��������A�o�^�[�̃t�H�g���A���\��
���^�o�[�X�̍��x���̂ЂƂƂ��āA�������������Ɠ����悤�Ɋ������Ԃ̎ʎ��I�ȍČ�������B��q�̓s�s�A���^���^�o�[�X�̂悤�ɁA���݂���ꏊ���T�C�o�[��ԂɍČ�������g�݂��i�߂��Ă���B���̏�ŁA���^�o�[�X�ł̎��g�̃A�o�^�[���A�l�Ԃ�������ɕ\���\�ȃo�[�`�����q���[�}������Ă���Ă���[22]�B�X�܂ł̐ڋq��ē��A����E���Ȃǂœ���I�Ɋ��p����A�l�Ɋ��Y�����݂Ƃ��ĎЉ�I�Ɏ�e�����悤�ɂȂ�B�o�[�`�����q���[�}���̃C���[�W��} 3‑48�Ɏ���[23]�B�o�[�`�����q���[�}���͐l�Ƃ̃C���^�t�F�[�X�Ƃ��Ă̖����݂̂ɗ��܂炸�A���i�̊��E�f�U�C���i�K�ɂ�����T���v������̃o�[�`���������A�T�v���C�`�F�[����DX���̎�i�Ƃ��Ă����L�����p�����悤�ɂȂ�[24]�B�܂��A�T�C�o�[��Ԃɂ����Ă͎��g�̃G�[�W�F���g���f�W�^���c�C���Ƃ��đ��݂��A�e�p�╞���͂������A�d����\������V�`���G�[�V�����ɉ����čœK�ɐ��䂳��A���Ƀr�W�l�X�V�[���ɂ����Ă͑Ζʈȏ�̃R�~���j�P�[�V������i�Ƃ��ē���I�Ɋ��p�����悤�ɂȂ�B

�} 3‑48�@�o�[�`�����q���[�}���̃C���[�W
���̂悤�Ȏʎ��I�ɕ\�����ꂽ�o�[�`�����q���[�}���́A���^�o�[�X�Ȃǂŗ��p�����X�}�[�g�t�H���ŕ\������ꍇ�A���̃f�o�C�X�̕`�揈���\�͂̐���A�T�[�o��CG�̕`�揈�����s���A���̌��ʂ�2D�f���Ƃ��ăX�g���[�~���O�z�M�����@����ʓI�ł���B���̍ۂɁA�f�[�^�ʐM�ʂ���ђ[���������ׂ��ۑ�ƂȂ邪�A�T�[�o�ƃX�}�[�g�t�H�����̕`�揈����K�ɕ��U���邱�Ƃɂ��A�X�}�[�g�t�H���ł̃t�H�g���A���ȃ����_�����O���\�Ƃ���Z�p����Ă���Ă���[22]�B����ɂ��A�ʐM�ʂ�}���X�}�[�g�t�H���ł̕\���i�����ێ����邱�Ƃ��\�ƂȂ�B
3.3.2.3�@ ���^�o�[�X��i��������}���`���[�_���A�g
���^�o�[�X�̍��x�����������邽�߂ɂ́A���o�I�ȕ\���͂̌��ゾ���łȂ��A���̓I�ȉ���ɂ�鎋���̌��A�l��m�ɐG��銴�o�Ȃǂ��Č����邱�Ƃ͏d�v�ł���B
�Ⴆ�A���^�o�[�X���ł̉��y���C�u�����̃��[�X�P�[�X�ɂ����ẮA�����I�ɗ��ꂽ��Ԃ�������܂߂ă��A���^�C���ɐڑ�����A�������������̏�ɂ��邩�̂悤�ȁA���C�u�����z�����v���̌����\�ɂȂ�Ƒz�肳���B
���̂悤�ȉ��̗��̓I�ȕ\������������Z�p�Ƃ��āAKDDI�́u����VR�v�Ƃ������̉����Z�p���Ă��Ă���B��Ԓ��̔C�ӂ͈̔͂ɃY�[��������������A���^�C���ɍ������邱�ƂŁA360�x�f�����̌������A�������������Ɏ��R���݂Ƀt�H�[�J�X�ł���C���^���N�e�B�u�����̌����\�ƂȂ��Ă���[25]�B�} 3‑49�́A���̉����Z�p�����p�����o�[�`�����R���T�[�g�̗�ł���B

�} 3‑49�@���̉����Z�p�����p�����o�[�`�����R���T�[�g�̗�
���o�⒮�o�ɉ����āA�G�o�A�k�o�A���o�̍Č��Z�p�Ƃ��g�ݍ��킹�邱�ƂŁA���^�o�[�X��ʂ��āA����̐�����āA���[�U�ɑ��Č܊��t�B�[�h�o�b�N������A���̌��Ƒ��F�̂Ȃ��A���R�ŖL���ȑ̌��A���邢�͌�����������̑̌��������邱�Ƃ����҂����B
3.3.3�@ �_�Q�f�[�^
3.3.3.1�@ �_�Q�f�[�^�Ƃ�
�ߔN�A3�����f�[�^�̐����E�����E�Ɋւ���Z�p�̔��W�ɔ����A�l�X�ȕ���ɂ�����3�����f�[�^�̗����p���i�߂��Ă���B�ł���\�I��3�����f�[�^�̂ЂƂɓ_�Q�f�[�^������B�_�Q�f�[�^�Ƃ́A3������ԓ��̕����̓_����Ȃ�f�[�^�̏W���ł���B�e�_�͍��W�ix,y,z�j�̊��ƐF�ir,g,b�j�┽�˗��Ȃǂ̑����������B�_�Q�f�[�^�͔��ɔėp���̍����\���`���ł��邽�߁A���L���p�r�ŗ��p�����B�Ⴆ�A���Ƃł͌�������n�`��LiDAR�Ȃǂ̃Z���T�ŃX�L�������A����ꂽ�_�Q�f�[�^���{�H����e�i���X�̉ߒ��ŗ��p����BAR/VR/MR�ȂǂɌ������R���e���c����ł́A�t�H�g�O�����g���Ȃǂ�p���Đ��������_�Q�f�[�^��3�����V�[���̕\���ɗ��p����B�܂��APC��^�u���b�g�A�X�}�[�g�t�H���A�w�b�h�}�E���g�f�B�X�v���C�ȂǁA�_�Q�f�[�^�������[�����p�r�ɉ����đ��l�����Ă���B���̂悤�ȏŁA��ʂɖc��ȃf�[�^�ʂƂȂ�_�Q�f�[�^�ɂ��X�g���[�W��ʐM�ւ̕��ׂ��팸���邽�߁A�_�Q���k�Z�p�ւ̊��҂����܂����B
���������w�i����A�}���`���f�B�A���������ەW�����c�̂ł���MPEG (Moving Picture Experts Group) �́A�_�Q���k�Z�p�ł���PCC (Point Cloud Compression) �̋K�i�����s���Ă���BPCC�͌��̓_�Q�̕i�����ێ����Ȃ���啝�Ȉ��k���\��B�����Ă���A�f�[�^�ʂ̑傫�ȓ_�Q�f�[�^�����k���ă��o�C������o�R�ň���I�ɓ`�����邱�Ƃ��\�ɂȂ����B����A�_�Q�̃G���R�[�h���̏������ׂɂ͉ۑ肪���������A�ŋ߂̊J������ł͍������Z�p�Ƃ̑g�ݍ��킹�ɂ�胊�A���^�C���������������Ă���B
�Ȃ��A���ەW���Ƃ��ċK�肳��Ă���͕̂��������݂̂ł���A�����������ɂ͖ړI�ɉ����čœK������]�n���c����Ă���B�܂�A�p�r�ɉ������p�t�H�[�}���X���������邽�߁A�_��Ȏ������\�ł���A�Ⴆ���A���^�C��������ڎw���ꍇ�́A�������̎d�g�݂Ƒg�ݍ��킹���G���R�[�_�̎������s����B
3.3.3.2�@ MPEG�ɂ��ŐV�̓_�Q���k�Z�p�̍��ەW������
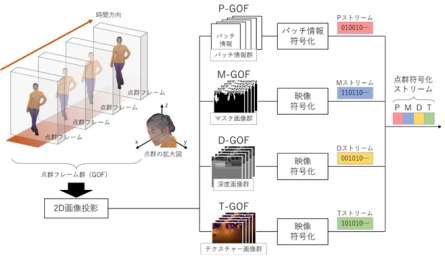
MPEG���K�i������PCC�ł́A�_�Q�f�[�^�̕��L���A�v���P�[�V�������l�����A�_�Q�f�[�^�̓����ɉ����āAV-PCC (Video-based�@Point Cloud Compression)��G-PCC (Geometry-based�@Point Cloud Compression)��2��������߂��Ă���B�ȉ��ɂ��ꂼ��ɂ��āA�����̊T���A�Ȃ�тɃ��A���^�C���G���R�[�_�̊J��������������B
�@ V-PCC (Video-based�@Point Cloud Compression)
V-PCC (Video-based�@Point Cloud Compression)[26] �́A���ەW�����@�ւ�ISO/IEC��2020�N10���ɋK�i�����ꂽ�B���O�ɁuVideo-based�v�Ƃ���ʂ�A�_�Q�f�[�^��̂悤�ɕϊ����āA�����̉f���������Z�p�ł���VVC (Versatile Video Coding)��HEVC (High Efficiency Video Coding)�𗘗p����_�������ł���B�_�Q�f�[�^�扻���鏈���̓s���ɂ��A�����̂���l���Ȃǂ̕��̂̓_�Q�̏����ɓK���Ă���B
V-PCC�͓����̂���l���Ȃǂ̕��̂̓_�Q�������悭���k�ł��邱�Ƃ���A�Ⴆ�A�t�H�g���A���Ȑl���\���ɂ�郉�C�u�R�}�[�X��V���[�ȂǁA��ɃR���e���c�z�M�ł̗��p�����҂����B���̂悤�ȃ��[�X�P�[�X�ł̓��A���^�C�������d�v�ƂȂ邪�A�_�Q�̃G���R�[�h���̏������ׂɂ͉ۑ肪�������B����ɑ��AV-PCC���A���^�C���G���R�[�_ [28],[29] �ł�MPEG�����J���Ă���Q�ƃ\�t�g�E�F�A [30] ���x�[�X�ɃG���R�[�_�ɑ��č������̎d�g�݂����A���A���^�C������\�ȃV�X�e�����J�������B
V-PCC�̃G���R�[�_�̏����̊T�v��} 3‑50�Ɏ����BV-PCC�̃G���R�[�_�́A�_�Q�t���[���QGOF (Group of Frames)�����͂����ƁA�e�_�Q�t���[�����p�b�`�ƌĂ��P�ʂɕ������A�_�Q�̎��͂ɉ��肵�������̖̂ʂɃp�b�`�𓊉e����B�p�b�`�ւ̕����Ɗe�p�b�`�̓��e�ʂ̔���́A�e�_�̖@�������Ȃǂ̏��Ɋ�Â����������B�p�b�`�̓��e�ɂ�蕡����ނ̉摜�����A���ꂼ��̉摜��GOF�P�ʂł܂Ƃ߂Ċ����̉f���������Z�p�ɂ�蕄��������B
����ɑ��AV-PCC���A���^�C���G���R�[�_�ł́A�p�b�`�ւ̕����Ɗe�p�b�`�̓��e�ʂ̔��菈���Ɋւ�����P���s�����B��̓I�ɂ́A�Q�ƃ\�t�g�E�F�A�ł͐��_���Ƃɂ��̔��菈�����s��ꂨ��A�c��ȏ������Ԃ���₳��Ă����̂ɑ��A3������Ԃ��p�b�`��������ɏ����ȏ���Ԃɕ������A���̏���Ԃ��Ƃɔ��菈�����s�����Ƃō����������B�����āAV-PCC�ɓK�����^�X�N�X�P�W���[�����O�����ɂ��CPU�g�p�������P�����B
�} 3‑50�@V-PCC�̃G���R�[�_����
����V-PCC���A���^�C���G���R�[�_��p�����V�X�e���Ŏ��ۂ̃��[�X�P�[�X��z�肵���`���������s�����B�V�X�e���̍\���C���[�W��} 3‑51�Ɏ����B���O�ɃX�^�W�I�ŎB�e�����l���̍����x�_�Q�i��2000���_/�b�j��V-PCC���A���^�C���R�[�f�b�N�ɂ���ĕ��������A5G���o�R���ĉ��u�̎������_�܂Ń��C�u�z�M�����B���u�n�ł̓z���O���t�B�b�N�X�e�[�W��X�}�[�g�t�H���ŃR���e���c������I�ɍĐ��ł��邱�Ƃ��m�F�����B
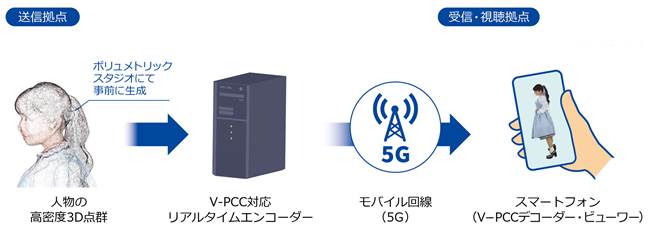
�} 3‑51�@V-PCC���A���^�C���`�������̃V�X�e���\��
V-PCC��p���ă��A���^�C���ɓ_�Q�f�[�^�̓`�����ł��邱�Ƃɂ��A�Ⴆ�Ή��y��t�@�b�V�����Ȃǂ̃V���[�C�x���g��ΏۂɁA�{�������g���b�N�X�^�W�I�ŎB�e�����f�������̂܂܃��^�o�[�X�ɎQ��������Ƃ������V�����C�x���g�̌��̑n�o�����҂ł���B
�A G-PCC (Geometry-based Point Cloud Compression)
G-PCC (Geometry-based Point Cloud Compression)[27] �́A���ەW�����@�ւ�ISO/IEC��2023�N3���ɋK�i�����ꂽ�BV-PCC�Ƃ͈قȂ�_�Q��3�����f�[�^�̂܂ܕ��������A�ǂ̂悤�ȓ_�Q�f�[�^�ɑ��Ă��g�p�\�ł���_�������ł���B�������Ȃǂ̐Î~�������̂��Ԃ�\���_�Q��ALiDAR�Ŏ擾�����_�Q�Ȃǂ̕��̂��Ԃ�\���a�ȓ_�Q�ɓK���Ă���B
G-PCC�́AV-PCC�ƈقȂ�L���3�����V�[���̓_�Q��LiDAR�Ŏ擾�����a�ȓ_�Q�ɑ��ē_�Q�̕i���Ȃ킸�����悭���k�ł��邱�Ƃ���A������x����ЊQ��ȂǕ��L�����p�����҂���Ă���B���̂悤�ȃ��[�X�P�[�X�ł́A���O�ɂ�����^�@��Ŏ擾�����_�Q���A���o�C��������o�R���đ����ɉ��u�n�ɓ`�����Ċm�F�ł��邱�Ƃ��]�܂����B�������Ȃ���AG-PCC�̏ꍇ�ɂ����Ă��_�Q�̃G���R�[�h���̏������ׂɂ͉ۑ肪�������B����ɑ��AG-PCC���A���^�C���G���R�[�_ [29] �ł�MPEG�����J���Ă���Q�ƃ\�t�g�E�F�A [31] ���x�[�X�ɃG���R�[�_�������Ƌ@�\�lj������{���A���A���^�C������\�ȃV�X�e�����J�������B
�����_�ŋK�i�����������Ă���G-PCC�́A�t���[�����̏������Ɨ����Ă���B���̂��߁A���͂������t���[������ꍇ�ɂ̓}���`�X���b�h�����ŕ���ɃG���R�[�h���邱�ƂŁA�V���O���X���b�h�̓��쎞�Ɠ������ʂ������ɓ��邱�Ƃ��ł���B������G-PCC���A���^�C���G���R�[�_�ł́A�t���[���P�ʂ̕������s�����Ƃō����������������B�܂��A�@�\�lj��Ƃ��āA�_�Q�f�[�^�̃X�g���[�~���O���o�͋@�\�ƃl�b�g���[�N����M�@�\�����������B����ɂ��m�[�gPC��8�����Ƃ����ꍇ��200���_/�b���鏈�����\�ɂȂ����B����́A�����̍����\LiDAR�Ŏ擾�ł���_�Q�����A���^�C���ŏ������邱�Ƃ��ł��鐫�\�ł���B
����G-PCC���A���^�C���G���R�[�_��p���ăV�X�e�����\�����A���ۂ̃��[�X�P�[�X��z�肵���`���������s�����B�V�X�e���̍\���C���[�W��} 3‑52�Ɏ����BLiDAR��RGB�J�����Ń��A���^�C���Ɏ擾���Ă���_�Q�f�[�^���m�[�gPC�ŃG���R�[�h���A5G���o�R���ĉ��u�n�ɓ`�������BLiDAR �́A��32 ���_/�b (3.2 ���_/�t���[���A10�t���[��/�b) �� �_�Q�f�[�^���擾���Ă����B���u�n�ł́A��M�����_�Q�f�[�^��PC��ʂɕ\�������B��M���ł́A�_�Q�f�[�^�擾�����500�~���b�̒x���ŁA�_�Q������I�ɍĐ��ł��邱�Ƃ��m�F�����B
G-PCC��p���ă��A���^�C���ɓ_�Q�f�[�^�̓`�����ł��邱�Ƃɂ��A�Ⴆ�h���[���𗘗p���Č���̗l�q�����C�u�z�M���A�ЊQ���̋~��������C���t���\�z���̉��u��Ǝx���̉~���������҂ł���B
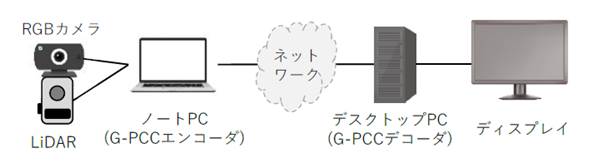
�} 3‑52�@G-PCC���A���^�C���`�������̃V�X�e���\��
3.3.4�@ �z���O���t�B
3.3.4.1�@ �z���O���t�B�Ƃ�
�z���O���t�B�Ƃ́A����Ԃɂ����Ėڂɓ͂����̔g���Č����邱�ƂŁu�������������������ɂ��邩�̂悤�Ɍ�����v���̉f���\�����\�Ƃ���Z�p�ł���A�u���ɂ̗��̉f���Z�p�v�Ƃ��Ă�Ă���B���̂���̌����Č����鐫������A�ዾ�Ȃǂ̃f�o�C�X���p��Ȃ����ᗧ�̉f���ӏ܂��\�ł���B�܂��A�z���O���t�B�͐l�Ԃ̗��̒m�o��4�v���i���ᎋ���E�^�������E�t�s�E�œ_���߁j�����ׂĖ������Z�p�Ƃ���Ă���A�]���̗��̉f���Z�p�Ƃ͈قȂ�A�u�t�s���ߖ����i�ӏ҂̓��鉜�s�����Ǝ��ۂ̃f�B�X�v���C�ʂƂ̋������ɖ����������邱�Ɓj���N����Ȃ��v�Ƃ�����������A�ᐸ��J��s�����Ȃǂ̊ӏ҂̐g�̓I���S�̏��Ȃ��f���Z�p�Ƃ��Ă����҂���Ă��� [32]�D��L���\��Ƃ��āA�z���O���t�B�͏]���̗��̉f���ɂ͂Ȃ�����������Ă���A���Y���̉f���ɂ���Ă����炳��郆�[�U�ϓ_�̃����b�g�͈ȉ��̒ʂ�ł���D
1. �����̂悤�ȗ��̊�����
2. �t�s���ߖ����ɂ��g�̓I���S���N����Ȃ�
3. �[�����m�ȉ��s�\�����\
4. ���[�U�̎��͂ɉ������Đ����̕���\
5. ���ߕ\���ɂ�����ԂƂ̏d�\
6. ���ᗧ�̉f���ӏ܂��\
�����̓�������A�z���O���t�B�̓��[�U���S�̏��Ȃ������Ԋӏ܉\�ȗ��ᗧ�̉f���ł���A����I�ȗ��p�������Ԃł̗��p�A���m�ȉ��s�������߂郆�[�X�P�[�X�ɓK���Ă���Ƃ����A��̓I��Ƃ��ẮA�ȉ��̃��[�X�P�[�X����������B
�i�P�j���̉f���L���E����
�@�z���O���t�B�́A�����̂悤�ȗ��̊�����f���\�����\�Ƃ��A�܂��[�����m�ȉ��s�\�����\�ł���Ƃ�����������A���̉f���L���ɉ��p���邱�ƂŃ��[�U�ւ̍����A�s�[�����ʂ����҂����B�܂��A������Ԃɂ����ė��̉f���ł̈ē��W���Ȃǂ̏����s�����ƂŁA��蒼���I�ȏ���̑��i�����҂����B
�i�Q�j���u�R�~���j�P�[�V����
�@�z���O���t�B�́A�����̂悤�ȗ��̊�����f���\���Ƃ�����������A���u�R�~���j�P�[�V�����ɂ�����f���\���ɗ��p���邱�ƂŁA�u��葊���g�߂Ɋ����鉓�u�R�~���j�P�[�V�����̎����v�����҂����B�e���r��c�Ȃǂɗ��p���邱�ƂŖȖ��ȃR�~���j�P�[�V�������������A�����I�ȓ������̎����ɂ���^����B
�i�R�j���u����
�z���O���t�B�ɂ������̂悤�ȗ��̊�����f���\���ɂ��A��蒼���I�ȋ�ԏ��̗����ɂȂ���B��̓I�ɂ́A�X�|�[�c�ɂ����鉓�u�w���Ȃǂɂ����āA�w���҂̓����𐳊m�ɗ����ł��邱�Ƃ���Ζʂł̎w���Ɠ����̎w�����ʂ̎��������҂����B�܂��A�g�̓I���S���N����Ȃ��Ƃ�����������A�q�������̋��狳�ނւ̉��p���\�ł���A���ʓI�ȉ��u����ɂ��n��i���̉����Ȃǂ����҂����B�@
�i�S�j���u���
�z���O���t�B�́A�[�����m�ȉ��s�\�����\�ł���Ƃ�����������A��荂�x�ȉ��u��Â̎��������҂����B��̓I�ɂ́A���u�n�ɂ����Ă������̏�Ԃ𗧑̓I�����m�Ɍ��邱�Ƃ��ł���悤�ɂȂ�A�ΖʂƂ���F�̂Ȃ��f�f���\�ƂȂ�B�܂��A���{�b�g����Z�p�ȂǂƑg�ݍ��킹�邱�ƂŁA���u�ł̎����Ȃǂ��\�ƂȂ邱�Ƃ����҂���A�����ɂ��A��Â̂���Ȃ鍂�x����n��i���̉��������҂����B
3.3.4.2�@ �z���O���t�B�̍Đ�
�z���O���t�B�̍Đ��ɂ������āA�ߔN�ł̓R���s���[�^��Ő��������f�B�W�^���f�[�^�u�v�Z�@�����z���O�����icomputer-generated hologram: CGH�j�v���u��Ԍ��ϒ���ispatial light modulator: SLM�j�v��ŕ\�����A���̉f�����Đ������@���L����������Ă���[33]�B�R���s���[�^���3D��ԏ�ɔz�u���ꂽ���̂���̌����V�~�����[�g����CGH��Ƃ�����������A�u�����ɑ��݂��Ȃ����z�I�ȕ��̂��ʑ̂Ƃ��邱�Ƃ��ł���v�A�u�f�B�W�^���f�[�^�Ƃ��ĉ��u�n�ւ̓`�������\�ƂȂ�v�Ƃ��������_������BCGH��p�������̉f���̍Đ��͎�Ɏ���3�̃v���Z�X����Ȃ�A���̃v���Z�X�̊T�v��} 3‑53�Ɏ����B
�i1�j���̌��f�[�^�̐���
�R���s���[�^�̉��z�I��3D��ԏ��3D���f���f�[�^�i���́j��z�u���A�ӏܑΏۂƂȂ�V�[���i�ӏܑΏۃV�[���j���\������B���̊ӏܑΏۃV�[���ɑ��āASLM�̈ʒu�ɑ������镽�ʁi�z���O�����ʁj��ݒ肷��B�ӏܑΏۃV�[���̕��̂���z���O�����ʂ��̓`���v�Z���s���A�z���O�����ʏ�̌��̐U���ʑ����z�i���̌��f�[�^�j��B���̂Ƃ��A���̌��f�[�^��2�������ʏ�ɕ��z����U���ƈʑ����i�������͂��̕��f���\���j�ƂȂ�B
�i2�jCGH�̐���
�@�z���O�����ʂɐ������ꂽ���̌��f�[�^�Ƃ͕ʂ̌����ł���Q�ƌ���ݒ肵�A���Y�Q�ƌ��ƕ��̌��f�[�^�̊��p�^�[�����Z�o����B���̊��p�^�[����CGH�ł���B���ۂ�SLM�ɂĕ\������ۂɂ́ACGH��2bit��8bit�̃r�b�g�[�x�����摜�ւƕϊ������B
�i3�jCGH��p�������̑��̍Đ�
�@CGH��SLM�ɕ\�����������ŁA�Q�ƌ��Ɠ��l�̈ʒu���瓯�l�̔g���������i�Đ��Ɩ����j���Ǝ˂���BCGH�̃p�^�[���ɏ]���čĐ��Ɩ�����SLM��ʼn�܂��邱�Ƃɂ���āA�ӏܑΏۃV�[���̗��̑����Đ������B
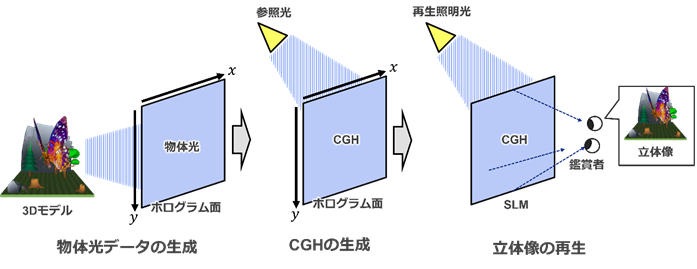
�} 3‑53�@�z���O���t�B�̍Đ��v���Z�X
3.3.4.3�@ �z���O���t�B�̋Z�p�ۑ�Ɠ���
�z���O���t�B�ɂ�闧�̉f���̎����ɂ͑傫���ȉ��̋Z�p�ۑ肪����B
�i1�j�f�B�X�v���C�̑�^���ƍL���扻
���̉f���ɂ����Ă̓f�B�X�v���C�T�C�Y�ƃ��[�U�̊ӏ܉\�͈́i����j�͏d�v�ȗv�f�̈�ł���B�z���O���t�B�̌�������A���[�U�̊ӏ܂���Đ����̎���́A�z���O�����̉�f�Ԃ̋����i��f�s�b�`�j�ɂ���Č��肳���B�Ⴆ�ΐԐF���̔g����620�`750nm�Ƃ���ƁA�����悻����30���ƂȂ闧�̉f�����������邽�߂ɂ́ACGH�̉�f�s�b�`�����Ȃ��Ƃ�1��m�i=1,000nm�j�ȉ��ł���K�v�����邱�Ƃ��킩��B����͋ɂ߂č���f���x�ȃf�B�X�v���C���K�v�ł��邱�Ƃ��Ӗ�����B����SLM�ɂ��ẮA�ŐV�̌����Z�p�ɂ����Ă��A�����I�ɉf���ӏܗp�r�Ƃ��ĉf�����\���y���߂�f�o�C�X�͎�������Ă��Ȃ�[33]�B
�@���̉ۑ�ɑ��āAKDDI�ł�SLM�ł͂Ȃ����[�U�[���\�O���t�B��p����CGH�����p���邱�ƂŁA��^���L�����CGH�A�j���[�V�������������Ă���[34]�B
�i2�j�f�[�^�T�C�Y�̈��k
��L(1)�̉ۑ�ɋL�ڂ��������x�ȃf�B�X�v���C�ɂ����ẮA�\�������f�[�^�̉�f�����c��ƂȂ�B�Ⴆ�A�c��10cm�~10cm�̃f�B�X�v���C�T�C�Y�ł́A��L1��m��f�s�b�`�����f�B�X�v���C�̉�f����10����f�ɂ��̂ڂ�B�����ɁA���̂悤�ȃf�B�X�v���C�����ɐ��������z���O�����̃f�[�^�T�C�Y���傫�Ȃ��̂ƂȂ�B�z���O������2�������ʂɂ�������̐U���ʑ��Ȃǂ̕��z�ŕ\������邽�߁A��ʂ̉摜�E�f���t�H�[�}�b�g�Ɛe�a���������A�����̉f���������Z�p��K�p���邱�Ƃ��\�ł���B����ŁACGH�̂��M�������͎��R�摜�Ƃ͑傫���قȂ�B���̂��߁A�����̉f���������Z�p��P����CGH�ɓK�p���������ł̓C���^�[�\���A�C���g���\���Ƃ������@�\�����ʓI�ɓ������A�����I�Ȉ��k�͓���B������āA���̌����L�^����ʒu�̋ߖT�ɐݒ肵����ŕ��������A�������Ńz���O�����ʂ��g��`������Ƃ������A�v���[�`����Ă���Ă��� [35]�B���Y�A�v���[�`�ɂ��ACGH�̐M�����������R�摜�ɋ߂Â����߁A�����̉f���������Z�p�����ʓI�ɓ������Ƃ�����Ă���B
�y�Q�l�����z
[1] �T����, �g�w��I�����C�����EVR�J�Â̖��J���h, ���{�o�[�`�������A���e�B�w�, 2020, 25��, 2��, p.35-43, 2020.
[2] https://universitybusiness.com/how-about-using-a-digital-avatar-on-a-virtual-campus/
[3] https://www.nikkei.com/article/DGXMZO60130810Z00C20A6I00000/
[4] https://news.kddi.com/kddi/corporate/newsrelease/2020/05/15/4437.html
[5] https://news.kddi.com/kddi/corporate/newsrelease/2019/08/28/3979.html
[6] https://news.kddi.com/kddi/corporate/newsrelease/2023/03/07/6588.html
[7] https://www.kddi-research.jp/newsrelease/2019/100702.html
[8] https://www.dolbyjapan.com/dolby-cinema
[9] https://www.sony.jp/feature/contents/220606/
[10] https://article.murata.com/ja-jp/article/miraisens-3d-haptics-technology-1
[11] https://www.senseglove.com/
[12] https://aromajoin.com/ja
[13] https://www.meiji.ac.jp/koho/press/6t5h7p0000342664.html
[14] https://group.ntt/jp/newsrelease/2018/11/26/181126d.html
[15] Yoneyama��, �gHolographic head-mounted display with correct accommodation and vergence stimuli, �gOpt. Eng. 57(6), 061619, 2018.
[16] https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r05/html/nd131210.html
[17] https://hello.vrchat.com/
[18] https://www.fortnite.com/
[19] https://adoption.microsoft.com/ja-jp/microsoft-mesh/
[20] https://about.meta.com/ja/
[21] https://cluster.mu/
[22] https://www.kddi-research.jp/newsrelease/2021/021801.html
[23] https://news.kddi.com/kddi/corporate/newsrelease/2021/03/10/5006.html
[24] https://news.kddi.com/kddi/corporate/topic/2021/09/10/5401.html
[25] �x����, �g�����҂��Ƃ̌������E�����������������鉹���f�B�A�Z�p�h, �M�w��, Vol.104, No.1, pp.22-26, 2021�N1��
[26] "V-PCC codec description", ISO/IEC JTC1/SC29/WG7 N0100 (June2020)
[27] "G-PCC codec description", ISO/IEC JTC1/SC29/WG7 N0217 (Apr.2022)
[28] https://www.kddi-research.jp/newsrelease/2022/102401.html
[29] https://www.kddi-research.jp/newsrelease/2023/012401.html
[30] https://github.com/MPEGGroup/mpeg-pcc-tmc2
[31] https://github.com/MPEGGroup/mpeg-pcc-tmc13
[32] D. M. Hoffman, A. R. Girshick, K. Akeley, and M. S. Banks, �gVergence–accommodation conflicts hinder visual performance and cause visual fatigue,�h J. Vis. 8(3), 33, 2008.
[33] ���c ���i�C��ԑ��Đ��p�\���f�o�C�X�̌����J�������CNHK�Z��R&D �H���CNo.187, 2021.
[34] https://www.kddi-research.jp/newsrelease/2022/050901.html
[35] ������,"VVC�ɂ��v�Z�@�����z���O�����̓��摜�������̈ꌟ��," 2024�N�d�q���ʐM�w������u���_���W, No.D-11A-34, 2024�N3��.
3.4�@ AI�ɂ��R���e���c�����Z�p
3.4.1�@ ����AI�Ƃ�
3.4.1.1�@ ����AI�̒�`
����AI�iGenerative Artificial Intelligence�j�́A�f�[�^�̊w�K��ʂ��ĐV�����A���m�̃f�[�^������\�͂����l�H�m�\�̈ꕪ��ł���B�]����AI�������̏��͂��A���ނ��邱�Ƃɏd�_��u���Ă����̂ɑ��A����AI�́A�w�K�����f�[�^����V���ȃR���e���c���u���ݏo���v�B���̃v���Z�X�́A�l�Ԃ��o����m������V�����A�C�f�A�ݏo�����@�Ƃ�����x�ގ����Ă���B
����AI�̊j�S�́u���f���v�ɂ���B����̓f�[�^�Z�b�g�͂��A���̃f�[�^�Z�b�g�ɐ��ރp�^�[���╪�z�𗝉�����\���ł���B���̗�������ɁA���f���͐V���ȃf�[�^�|�C���g�����邱�Ƃ��ł���B�Ⴆ�A�����̔L�̉摜����w�K�����������f���́A���݂��Ȃ������A���Ɍ�����L�̉摜�����邱�Ƃ��\�ł���B
����AI�́A����Generative Adversarial Networks�iGANs�j��Variational Autoencoders�iVAEs�j�Ƃ������Z�p�̐i���ɂ��A���ڂ��W�߂Ă���B�����̋Z�p�́A���A���e�B�̂���摜�A�����A�e�L�X�g�����邾���łȂ��A�f�[�^�g���A���z���̃V�~�����[�V�����A���������ꂽ�f�[�^�Z�b�g�̍쐬�ȂǁA����ɂ킽�鉞�p���\�ɂ��Ă���B
�������A����AI�̔\�͂͑n���Ɍ��肳��Ȃ��B���̋Z�p�́A�f�[�^�̗�����[�߁A��������p����V�������@����邱�ƂŁA�Ȋw�A��ÁA�|�p�Ȃǂ̕���Ɋv�V�������炷���Ƃ����҂���Ă���B����AI���J���\���͑傫���A���̉e���͉�X�̐����̂����鑤�ʂɋy�Ԃ��낤�B
3.4.1.2�@ ����AI�����j�Ɣ��W
����AI�̗��j�́A�l�H�m�\�����̏����ɑk�邱�Ƃ��ł���B�ŏ��̐l�H�m�\�v���O�����̈ꕔ�́A�ȒP�Ȍ���p�^�[���̐����␔�w�I�ؖ��̐����Ȃǂ����s���邱�Ƃ�ړI�Ƃ��Ă����B�������A�����̏����̎��g�݂͌���I�Ȃ��̂ł���A����AI�̉\�������S�Ɉ����o�����Ƃ͂ł��Ȃ������B
����AI�̌����ɂ�����傫�ȓ]���_�́A�[�w�w�K�ƃj���[�����l�b�g���[�N�̐i���ɂ���Ă����炳�ꂽ�B���ɁA2014�N�ɓ������ꂽGenerative Adversarial Networks�iGANs�j�́A����AI�̕���Ɋv���������炵���BGANs�́A������Ǝ��ʊ�̓�̃j���[�����l�b�g���[�N���݂��ɋ������Ȃ���w�K��i�߂�d�g�݂ł���A���Ƀ��A���ȉ摜��r�f�I�A����������\�͂����B
���̌�̔N�����o�āA���l�Ȑ������f�����J������A���ꂼ�ꂪ�قȂ�A�v���[�`�Ńf�[�^�̐������s���悤�ɂȂ����B�Ⴆ�AVariational Autoencoders�iVAEs�j�́A�f�[�^�̊m���I���f�����w�K���A���̃��f������V�����f�[�^���T���v�����O����B����ARecurrent Neural Networks�iRNNs�j�́A���Ƀe�L�X�g�≹�y�̐����ɂ����ėD�ꂽ���\������B�����͌�ɉ������B
����AI�̉��p�͈͂��}���Ɋg�債�Ă���B�����̉摜��������n�܂�A���݂ł͎��R���ꐶ���A3D���f���̐����A��É摜�̍����ȂǁA����ɂ킽�镪��ł̉��p���i��ł���B���̂悤�Ȑi���́A����AI�������E�̖������ɂ����ďd�v�Ȗ������ʂ����\���������Ă���B
����AI�̗��j�Ɣ��W�́A�l�H�m�\�Z�p�̐i���ƂƂ��ɁA�������̑n�����ƃC�m�x�[�V�����̌��E���g���������Ă���B
3.4.1.3�@ ����AI�̊�{�T�O
�@ �@�B�w�K�Ɛ���AI�̊W
�@�B�w�K�́A�f�[�^����w�K���A���̊w�K��ʂ��ē���̃^�X�N�����s����\�͂��R���s���[�^�ɗ^����Z�p����ł���B���̍L�͂ȕ���̒��ŁA����AI�͋@�B�w�K�̂����̓��ʂȃJ�e�S���Ɉʒu�Â�����B�@�B�w�K���f�[�^�͂��A�p�^�[����F�����邱�Ƃɒ��͂���̂ɑ��A����AI�͂��̃p�^�[������ɐV���ȃf�[�^�����邱�Ƃ�ړI�Ƃ��Ă���B
�@�B�w�K���f���́A��ʂɓ��̓f�[�^�ɑ��ė\���╪�ނ��s�����A����AI�̃��f���́A�^����ꂽ�f�[�^�Z�b�g�Ɋ�Â��ĐV�����f�[�^�C���X�^���X���u�����v����B���̈Ⴂ�́A���҂��Nj�����ړI�̍��{�I�ȈႢ���痈�Ă���B�@�B�w�K�̑����͗\���I�Ȑ����������A����AI�͑n���I�Ȑ��������B
����AI�̃��f���́A�@�B�w�K�̋Z�p�𗘗p���ăf�[�^�̕��z���w�K����B�w�K���ꂽ�f�[�^�̕��z����V�����T���v�������邱�ƂŁA���f���͎��ۂɑ��݂��邩������Ȃ����A�܂��ϑ�����Ă��Ȃ��f�[�^�|�C���g��z�����邱�Ƃ��ł���B���̃v���Z�X�́A�@�B�w�K�ɂ����鋳�t�Ȃ��w�K�̈�`�Ԃƌ��Ȃ����Ƃ��ł���B
�@�B�w�K�̘g�g�݂̒��ŁA����AI�͐V�����\�����J���B����AI�̃A�v���[�`�́A�]���̋@�B�w�K�����ʂ��Ă����������̖��A�Ⴆ�f�[�^�s����ߏ�K���Ȃǂ��ɘa�����i�����B�܂��A�@�B�w�K�����ݏo�����m�����A���S�ɐV�������@�Ŋ��p���邱�Ƃ��\�ɂ���B
�@�B�w�K�Ɛ���AI�̊W����T��A����AI���@�B�w�K�͈͓̔��łǂ̂悤�ɓ��ʂȈʒu���߂Ă��邩���������B�܂��A����AI�̊�{�I�ȊT�O�Ƃ��̋@�\�ɂ��Ă��ڍׂɐ�������B
3.4.1.4�@ �������f���̎��
�@ ���t����w�K�Ƌ��t�Ȃ��w�K
�@�B�w�K�̎�@�͑傫����ɕ�������B��͋��t����w�K�A������͋��t�Ȃ��w�K�ł���B�����͊w�K����ۂ̃f�[�^�̌`�ԂƁA���f�����ǂ̂悤�Ƀf�[�^����w�K���邩�Ɋ�Â��ċ�ʂ����B
���t����w�K�ł́A���f���͓��̓f�[�^�Ƃ���ɑΉ�����o�̓f�[�^�i���x���j�̗�������w�K����B���̃v���Z�X�ł́A���f�����������o�͂�����悤�ɁA���̓f�[�^�Əo�̓f�[�^�̊W�𗝉����邱�Ƃ��ړI�ł���B���t����w�K�̓T�^�I�ȗ�Ƃ��ẮA�摜�Ɏʂ��Ă��镨�̂����ʂ��镪�ޖ���A�����������Ƃ̉��i��\�������A���Ȃǂ�����B
����A���t�Ȃ��w�K�ł́A�o�̓f�[�^�i���x���j�Ȃ��œ��̓f�[�^�݂̂���w�K���s���B���̏ꍇ�A���f���̓f�[�^���̍\����p�^�[���������I�Ɍ����o���A����Ɋ�Â��ăf�[�^�ނ�����A�V�����f�[�^�������肷��B���t�Ȃ��w�K�́A�f�[�^�̃N���X�^�����O�⎟���팸�A�����Đ���AI�ɂ����鐶�����f���̊w�K�ɗ��p�����B
����AI�ɂ����鋳�t�Ȃ��w�K�̉��p�͓��ɏd�v�ł���B�������f���́A���x���t������Ă��Ȃ���ʂ̃f�[�^���畡�G�ȃf�[�^���z���w�K���A���̕��z�Ɋ�Â��ĐV�����f�[�^�C���X�^���X������B����ɂ��A���t�Ȃ��w�K�́A�V�����R���e���c�̐����A�f�[�^�g���A����ɂ͋��t����w�K���f���̃g���[�j���O�f�[�^�Ƃ��Ă̗��p�ȂǁA����ɂ킽�鉞�p���\�ƂȂ�B
�A GAN(Generative Adversarial Networks)
GAN�A���Ȃ킿Generative Adversarial Networks�́A2014�N�ɃC�A���E�O�b�h�t�F���[��ɂ���Ē�Ă��ꂽ�������f���ł���B���̃��f���́A������iGenerator�j�Ǝ��ʊ�iDiscriminator�j�̓�̃l�b�g���[�N����\�������B������͐V�����f�[�^�T���v������������������A���ʊ�͂��̃T���v�����{���̃f�[�^���������ꂽ�f�[�^�������ʂ�����������B
GAN�̊w�K�v���Z�X�́A������Ǝ��ʊ킪�݂��ɋ�������Q�[���̂悤�Ȍ`�Ői�ށB������͂��{���炵���f�[�^�����悤�Ǝ��݁A���ʊ�͖{���̃f�[�^�Ɛ������ꂽ�f�[�^�𐳊m�Ɏ��ʂ��悤�Ƃ���B���̋�����ʂ��āA������͏��X�ɍ��i���ȃf�[�^������\�͂����コ���A���ʊ�͂�萸�x�������ʂ���\�͂����コ����B
GAN�͓��ɉ摜�����ɂ����Č����Ȑ��ʂ��グ�Ă���A�ʐ^�̂悤�Ƀ��A���ȉ摜�����邱�Ƃ��ł���悤�ɂȂ����B�܂��A�X�^�C���ϊ��A�摜�⊮�A�摜����摜�ւ̕ϊ��ȂǁA���l�ȉ��p���\�ł���B
�������AGAN�̊w�K�͕s����ł���A���[�h����ƌĂ�錻�ۂ��N���邱�Ƃ�����B����́A�����킪����ꂽ��ނ̃T���v�������������Ȃ��Ȃ��Ԃ��w���B����ɁA���i���Ȑ������邽�߂ɂ́A�T�d�ȃp�����[�^�̒������K�v�ƂȂ�B
GAN�̌����́A���̃|�e���V�����Ɖ��p�̍L����ɂ��A����AI����ɂ����Ċ����ɍs���Ă���B�V�����A�[�L�e�N�`���̊J����A�w�K�v���Z�X�̈��艻�A���p�͈͂̊g��ȂǁA�����̐i����������B
�B VAE(Variational Autoencoders)
VAE�A���Ȃ킿Variational Autoencoders�́A�f�[�^�̊m�����z���w�K���邱�Ƃɂ��A�V�����f�[�^�����鐶�����f���ł���BVAE�̓I�[�g�G���R�[�_�̈�`�Ԃł���A�G���R�[�_�ƃf�R�[�_�̓�̎�v�ȕ�������\�������B�G���R�[�_�͓��̓f�[�^�����̐���ԂɃ}�b�s���O���A�f�R�[�_�͂��̐���Ԃ��猳�̃f�[�^��Ԃւ̃}�b�s���O���w�K����B
VAE�̓����́A����Ԃɂ�����_���L�Ӌ`�ȕ��@�ŘA�����Ă��邱�Ƃł���B����ɂ��A���ݕϐ��𑀍삷�邱�ƂŁA�f�[�^�̊��炩�ȕω������邱�Ƃ��\�ƂȂ�B�Ⴆ�A��摜�̐����ɂ����āA���ݕϐ���ω������邱�ƂŁA�\��┯�^���A���I�ɕς��摜���ł���B
VAE�̊w�K�v���Z�X�ł́A�G���R�[�_�ɂ���ăf�[�^�̊m�����z���ߎ����A�f�R�[�_�͂��̕��z����T���v�����O���ꂽ���ݕϐ������̃f�[�^�ɍč\������B���̉ߒ��ŁAKL�_�C�o�[�W�F���X�ƌĂ�鑹�������ŏ������邱�Ƃɂ��A�G���R�[�_�̋ߎ����z���f�[�^�̐^�̕��z�ɋ߂Â��悤�Ɋw�K���i�ށB
VAE�͂��̏_��ƌ���������A�摜���������łȂ��A�ُ팟�o�A�f�[�^�̈��k�A����ɂ͋����w�K�ɂ������ԕ\���̊w�K�ȂǁA���L�����p���\�ł���B�܂��A����Ԃ̉��߉\���́A�f�[�^�̗�����[�߂邽�߂̗L�p�Ȏ�i�����B
�������AVAE�ɂ͌��E������B�č\�����ꂽ�f�[�^�����̃f�[�^�ɔ�ׂĂڂ₯�Ă��܂��X��������A����͓��ɉ摜�f�[�^�ɂ����Č����ł���B�܂��A���G�ȃf�[�^�\�������f�[�^�̐����ɂ͓K���Ă��Ȃ��ꍇ������B
VAE�̌����́A��荂�i���Ȑ������邽�߂̐V�����A�[�L�e�N�`����w�K��@�̊J���ɏœ_�ĂĐi�߂��Ă���BVAE�̊T�O�́A����AI�̕���ɂ����ďd�v�Ȗ������ʂ���������ł��낤�B
�C RNN(Recurrent Neural Networks)
RNN�A���Ȃ킿Recurrent Neural Networks�́A���n��f�[�^�⏇���t����ꂽ�f�[�^���������߂̃j���[�����l�b�g���[�N�̈��ł���BRNN�̓����́A�ߋ��̏����L�����A��������݂̓��͂Ƒg�ݍ��킹�ď�������\�͂ɂ���B���̓����ɂ��ARNN�͎��R���ꏈ���≹�y�����ȂǁA�A���I�ȃf�[�^���ւ��^�X�N�ɓK���Ă���B
RNN�̊�{�I�ȍ\���̓V���v���ł��邪�A�����Ƀ��[�v�������ƂŁA���n��̊e���_�ł̓��͂ƂƂ��ɁA��O�̎��_����̏��������p�����Ƃ��ł���B����ɂ��ARNN�͕�����V�[�P���X���̈ˑ��W�����f��������\�͂����B
RNN�͓��ɐ������f���̕����ŗL���ł���B�ߋ��̃f�[�^�|�C���g���l�����Ȃ���V�����f�[�^�|�C���g������������邱�ƂŁA���͂���f�B�Ȃǂ̘A�������f�[�^�����邱�Ƃ��\�ƂȂ�B�Ⴆ�A�^����ꂽ�e�L�X�g�̑�����������A�����Ɋ�Â��ĐV�������y����Ȃ����肷�邱�Ƃ��ł���B
�������ARNN�ɂ͂������̉ۑ�����݂���B���ɁA�����Ԃ̈ˑ��W�𑨂��邱�Ƃ�����ł���Ƃ�����肪����B����͌��z����������z�������Ɗ֘A���Ă���A�w�K�ߒ��ŏd�v�ȏ�����邱�Ƃ������ł���B���̖����������邽�߂ɁALSTM(Long Short-Term Memory)��GRU(Gated Recurrent Unit)�Ȃǂ̉��ǂ��ꂽRNN���J������Ă���B
RNN�Ƃ��̕ώ�́A����AI�̕���ɂ����ďd�v�ȃc�[���ł��葱���Ă���B�������l�������f�[�^�����̔\�͂́A�����̉��p�ɂ����ĉ��l�����BRNN�̌����ƊJ���́A�����ʓI�ŏ_��ȃ��f����ڎw���Đi�߂��Ă���B
3.4.2�@ ����AI�̋Z�p�I�v�f
3.4.2.1�@ �f�B�[�v���[�j���O�Ɛ���AI
�f�B�[�v���[�j���O�́A�[�w�j���[�����l�b�g���[�N��p�����@�B�w�K�̈ꕪ��ł���A�ߔN�A����AI�̐i�W�ɂ����Ē��S�I�Ȗ������ʂ����Ă���B�f�B�[�v���[�j���O�̃��f���́A�����̑w�������ƂŁA���G�ȃf�[�^�̕\�����w�K����\�͂�����B���̔\�͂ɂ��A�f�B�[�v���[�j���O�́A�摜�A�����A�e�L�X�g�ȂǁA���l�ȃf�[�^�̐����ɓK���Ă���B
����AI�ɂ�����f�B�[�v���[�j���O�̉��p�́A��ɐ������f���̍\�z�Ɋւ��B�[�w�j���[�����l�b�g���[�N��p���邱�ƂŁA���x�ɕ��G�ȃf�[�^���z�����f�������A�V�����f�[�^�C���X�^���X�����邱�Ƃ��\�ƂȂ�B����GAN��VAE�Ȃǂ̐������f���́A�f�B�[�v���[�j���O�̘g�g�݂̒��Ŕ��W���Ă���A���A���ȉ摜�⎩�R�Ȍ���e�L�X�g�̐����ɐ������Ă���B
�f�B�[�v���[�j���O�ɂ�鐶��AI�̃A�v���[�`�́A�f�[�^�̊K�w�I�ȕ\�����w�K���邱�ƂɊ�Â��Ă���B�j���[�����l�b�g���[�N�̊e�w�́A���̓f�[�^�̈قȂ�����𑨂��A�����̓�����g�ݍ��킹�邱�Ƃŕ��G�ȃf�[�^�\����͕킷��B���̃v���Z�X�́A�l�Ԃ̔]����������������@�ɗގ����Ă���Ƃ��l�����Ă���B
�f�B�[�v���[�j���O��p��������AI�́A�D�ꂽ���ʂ��グ�Ă������ŁA��ʂ̃g���[�j���O�f�[�^�ƌv�Z������K�v�Ƃ���B�܂��A�������ꂽ�f�[�^�����̃f�[�^�Z�b�g�Ɋ܂܂���f���邱�Ƃ�A���ߐ��̌��@�ȂǁA�������̉ۑ�����݂���B
�f�B�[�v���[�j���O�Ɛ���AI�̊W�́A�����AI�Z�p�̔��W�ɂ����ďd�v�ȃe�[�}�ł��葱����B�����҂����́A�������I�ȃ��f���̊J���A�f�[�^�̕�ւ̑Ώ��A���f���̉��ߐ�����ȂǁA�����̉ۑ�Ɏ��g��ł���B
3.4.2.2�@ �j���[�����l�b�g���[�N�̃A�[�L�e�N�`��
�j���[�����l�b�g���[�N�̃A�[�L�e�N�`���́A����AI�ɂ����钆�j�I�ȗv�f�ł���B����́A�f�[�^���畡�G�ȓ�����p�^�[�����w�K���A�V���ȃf�[�^�����邽�߂̌v�Z���f���̍\�����w���B�j���[�����l�b�g���[�N�́A�P���ȃp�[�Z�v�g�������畡�G�Ȑ[�w�w�K���f���܂ŁA���܂��܂Ȍ`�Ԃ����݂���B
��ʂɁA�j���[�����l�b�g���[�N�͓��͑w�A�B��w�A�o�͑w�̎O�̎�v�ȑw����\�������B���͑w�̓f�[�^�����A�B��w�͕����̃��x���Ńf�[�^�̒��ۉ��Ɠ������o���s���A�o�͑w�͍ŏI�I�Ȍ��ʂ����B�B��w�̐��ƃm�[�h�i�j���[�����j�̐��������قǁA�l�b�g���[�N�͂�蕡�G�Ȋ���\���ł��邪�A�v�Z�R�X�g�Ɖߊw�K�̃��X�N�����傷��B
�j���[�����l�b�g���[�N�̃A�[�L�e�N�`���́A�^�X�N�̐����A�g�p����f�[�^�̎�ށA���߂���o�͂ɂ���đ傫���قȂ�B�[�w�w�K�ɂ�����ŐV�̐i���́A����̃^�X�N�ɍœK�����ꂽ�A�[�L�e�N�`���̊J���ɂ���Ă����炳��Ă���B�Ⴆ�A��ݍ��݃j���[�����l�b�g���[�N�iCNN�j�͉摜�֘A�̃^�X�N�ɁA�g�����X�t�H�[�}�[���f���͎��R���ꏈ���̃^�X�N�ɓ������Ă���B
�j���[�����l�b�g���[�N�̃A�[�L�e�N�`���̐v�ƍœK���́A����AI�̐��\�����肷���ŏd�v�ȗv�f�ł���B�����҂����́A�������I�ŁA�\���͖L���ŁA�w�K�����肷��l�b�g���[�N�A�[�L�e�N�`�������߂āA�p���I�ɐV���ȃ��f���̊J���Ɏ��g��ł���B
3.4.2.3�@ �������ƍœK��
�������́A�j���[�����l�b�g���[�N�̊w�K�ɂ����āA���f���̏o�͂��ڕW�Ƃ���l����ǂꂾ������Ă��邩���ʉ�����w�W�ł���B����AI�ɂ����āA�������̓��f�������������f�[�^���{���̃f�[�^�Ƃǂꂾ�����Ă��邩�A�܂��͓���̖ړI���ǂꂾ���B�����Ă��邩��]�����邽�߂ɗp������B�œK���Ƃ́A���̑������̒l���ŏ�������悤�Ƀ��f���̃p�����[�^������v���Z�X�ł���B
����AI�ɂ����鑹�����͑��푽�l�ł���A����̐������f����^�X�N�ɉ����ĈقȂ�B�Ⴆ�AGAN�ł́A���ʊ킪�{���̃f�[�^�Ɛ������ꂽ�f�[�^���ǂꂾ�����m�Ɏ��ʂł��邩��\���������ƁA�����킪���ʊ���x�����Ƃɂǂꂾ���������Ă��邩��\�����������p������BVAE�ł́A�č\���덷��KL�_�C�o�[�W�F���X���܂ޑ��������g�p����A�f�[�^�̍č\�����x�Ɛ���Ԃ̐��������ɍs���B
�œK���A���S���Y���́A�������̍ŏ����������I�ɍs�����߂̎�@�ł���A���z�~���@�₻�̕ώ킪��ʓI�Ɏg�p�����B���z�~���@�́A�������̌��z�A�܂�p�����[�^�Ɋւ��鑹�����̓������v�Z���A���̌��z�����������Ƀp�����[�^���������X�V���Ă����B���̃v���Z�X���J��Ԃ����ƂŁA�ŏI�I�ɑ��������ŏ��ƂȂ�p�����[�^�̒l�Ɏ���������B
�œK���̉ߒ��ł́A�w�K���̐ݒ肪�d�v�ł���A����͊e�X�e�b�v�Ńp�����[�^���ǂꂾ���X�V���邩�����肷��B�w�K�����傫������ƍœK�ȉ����I�[�o�[�V���[�g���Ă��܂��A����������Ǝ����܂łɎ��Ԃ������肷����B�܂��A�~�j�o�b�`���z�~���@������^����p���邱�ƂŁA�w�K�̈��萫�����コ���A�������x�𑁂߂邱�Ƃ��ł���B
�������ƍœK���́A����AI�ɂ����郂�f���̐��\�Ɗw�K���������肷���ŏd�v�ȗv�f�ł���B�����҂����́A���ǂ��������邽�߂ɁA�V�����������̐v��œK���A���S���Y���̉��ǂɎ��g��ł���B
3.4.3�@ ����AI�̉��p��
3.4.3.1�@ ���R���ꐶ��
���R���ꐶ���́A����AI�����p������\�I�ȗ̈�̈�ł���B����́A�@�B���l�Ԃ������ł��錾��Ńe�L�X�g��������������Z�p�ł���A�f�[�^�̗v��A���̍쐬�A��b�^�G�[�W�F���g�A�X�g�[���[�̑n��ȂǁA����ɂ킽�鉞�p�����݂���B
���R���ꐶ���̃v���Z�X�́A��ʂɃf�[�^��Ӑ}���ꂽ���b�Z�[�W����͂Ƃ��Ď��A��������Ƃɕ��╶�͂��\�z����B���̉ߒ��ł́A���@�I�ɐ��m�ŁA���Ӗ����ʂ���e�L�X�g�����邱�Ƃ����߂���B����AI�Z�p�A����RNN��g�����X�t�H�[�}�[���f���Ȃǂ̐[�w�w�K���f���́A���̃^�X�N�ɂ����ďd�v�Ȗ������ʂ����B
���R���ꐶ���̉��p��Ƃ��ẮA�V�C�\��A�X�|�[�c�C�x���g�̌��ʁA�����̗v��Ȃǂ�����B�����̉��p�ɂ����āA����AI�͑�ʂ̃f�[�^����֘A���𒊏o���A�����l�Ԃ��������₷���`���̃e�L�X�g�ɕϊ�����B�܂��A�`���b�g�{�b�g�≼�z�A�V�X�^���g�ł́A���[�U�[�̎����v�]�ɑ��鎩�R�ȕԓ������邽�߂ɂ��̋Z�p���p������B
���R���ꐶ���̋Z�p�́A�N���G�C�e�B�u�ȕ��|��i�̑n��ɂ����p����Ă���B�Ⴆ�A�����̕��w��i�̃X�^�C����͕킵�ĐV���ȕ�������邱�Ƃ�A���[�U�[����̃v�����v�g�Ɋ�Â��Ď��⏬����n�삷�邱�Ƃ��\�ł���B
���R���ꐶ���Z�p�̔��W�ɂ��A�e�L�X�g�����̎��������i�݁A�����̎Y�Ƃɂ����č�Ƃ̌��������}���Ă���B�������A�������ꂽ�e�L�X�g�̕i���╶���̓K����ۏ��邱�ƁA�����������e�̗ϗ������m�ۂ��邱�ƂȂǁA�������ׂ��ۑ�������B�����҂�J���҂́A�����̉ۑ�ɑΏ����Ȃ���A��荂�x�Ȏ��R���ꐶ���Z�p�̊J���Ɏ��g��ł���B
3.4.3.2�@ �摜�����ƕҏW
�摜�����ƕҏW�́A����AI�Z�p�������Ȑ��ʂ������Ă��镪��ł���B���̋Z�p�́A�w�K�����摜�f�[�^�̕��z����V�����摜������\�͂Ɋ�Â��Ă���B����GAN��VAE�Ȃǂ̐[�w�w�K���f���́A�ʐ^���A���ȉ摜�̐����ɐ������Ă���A�A�[�g�A�G���^�[�e�C�����g�A�L���ȂǁA���l�ȗ̈�ł̉��p���i��ł���B
�摜�����ɂ����鉞�p��Ƃ��ẮA�L�����N�^�[�f�U�C���A���i�摜�̐����A�t�@�b�V�����A�C�e���̃f�U�C���Ȃǂ�����B�����̉��p�ɂ����āA����AI�͐l�Ԃ̑n�������x�����A�V���ȃr�W���A���R���e���c�̑n�o���\�ɂ���B
�摜�ҏW�ɂ����Ă��A����AI�͑傫�ȉ\�����߂Ă���B�Ⴆ�A�����̉摜�̃X�^�C����ϊ�������A�摜�̈ꕔ�����R�ɏC���E�폜������A���𑜓x�����邱�Ƃ��ł���B����ɂ��A�]���͐��Ƃ̎�ɂ���Ă̂݉\�ł��������x�ȉ摜�ҏW���A����y�ɁA�������I�ɍs����悤�ɂȂ�B
�܂��A�摜�����Z�p�́A���z������g�������Ƃ���������ɂ����Ă��d�v�Ȗ������ʂ����Ă���B���A���Ȋ���I�u�W�F�N�g�����A���������z��Ԃɓ������邱�ƂŁA�v���^�̑̌�����邱�Ƃ��ł���B
�摜�����ƕҏW�Z�p�̔��W�ɂ́A�ϗ��I�ȉۑ�������B���ɁA���A���Ȑl���摜��f��������\�͂́A���U�̏��̊g�U��v���C�o�V�[�̐N�Q�Ɉ��p�����\��������B���̂��߁A�Z�p�̊J���Ɖ��p�ɂ������ẮA���̎Љ�I�ȉe�����\���ɍl�����A�K�ȃK�C�h���C���̂��Ƃōs���K�v������B
�摜�����ƕҏW�́A����AI�̉��p�̒��ł����Ɏ��o�I�ɖ��͓I�ȕ���ł���A������Z�p�̐i���ƂƂ��ɁA����ɑ��l�ȉ��p�����҂���Ă���B�} 3‑54�͑�\�I�ȉ摜�����A�v���P�[�V����Stable Diffusion�Ő����������{�̉���̕��i�̗�ł���B

�} 3‑54�@Stable Diffusion�Ő�����������̕��i
3.4.3.3�@ ���������Ɖ��y����
���������Ɖ��y�����́A����AI�Z�p�����p�����d�v�ȗ̈�ł���B�����̋Z�p�́A�e�L�X�g���玩�R�ȉ�����������A�V�����y�Ȃ�n�삵���肷�邱�Ƃ��\�ɂ���B
���������A���Ȃ킿�e�L�X�g�E�g�D�E�X�s�[�`�iTTS�j�́A�����ꂽ�e�L�X�g��l�Ԃ̐��ɕϊ�����Z�p�ł���B�ߔN�̐���AI�̐i���ɂ��A���������̕i���͑傫�����サ�Ă���A�����A�C���g�l�[�V�����A����\���ȂǁA�l�Ԃ̎��R�Șb������͕킷�邱�Ƃ��\�ƂȂ��Ă���B���̋Z�p�́A�����A�V�X�^���g�A�I�[�f�B�I�u�b�N�̐����A���o��Q�Ҏx���V�X�e���ȂǁA����ɂ킽�鉞�p������B
���y�����ɂ����Ă��A����AI�͐V���ȉ\�����J���Ă���BAI�́A����̃W��������A�[�e�B�X�g�̃X�^�C�����w�K���A����Ɋ�Â��ăI���W�i���̊y�Ȃ�n�삷�邱�Ƃ��ł���B���̃v���Z�X�ɂ́A�����f�B�A�n�[���j�[�A���Y���ȂǁA�y�Ȃ̂��܂��܂ȗv�f���܂܂��B�������ꂽ���y�́A�f���Q�[���̃T�E���h�g���b�N�A�A�[�e�B�X�g�̑n�슈���A����ɂ͉��y����ɂ����Ă����p�����B
���������Ɖ��y�����̐i�W�́A����AI�̔\�͂������ƂƂ��ɁA�N���G�C�e�B�u�ȕ���ɂ�����AI�̖������Ē�`���Ă���BAI�ɂ�鉹���≹�y�̐����́A�l�Ԃ̑n�������g�����A�V�����A�[�g�t�H�[���̒T���𑣂��Ă���B
�������A�����̋Z�p�̉��p�ɂ́A���쌠��n�앨�̃I���W�i���e�B�Ƃ������ۑ�������BAI���������������≹�y���l�Ԃ̃N���G�C�^�[�̌�����N�Q���Ȃ��悤�A�K�Șg�g�݂̂��ƂŋZ�p���g�p����邱�Ƃ����߂���B
���������Ɖ��y�����́A����AI�̉��p�Ƃ��đ傫�Ȓ��ڂ��W�߂Ă���A������Z�p�̔��W�Ƌ��ɁA���̉��p�͈͍͂L���葱����ł��낤�B
3.4.3.4�@ �f�[�^�g��
�f�[�^�g���́A�����̃f�[�^�Z�b�g����lj��̃g���[�j���O�T���v���������@�ł���A���ɋ@�B�w�K���f���̊w�K�ɂ����ďd�v�Ȗ������ʂ����B����AI�́A���̃v���Z�X�ɂ����Ē��S�I�ȋZ�p�ƂȂ��Ă���B�f�[�^�g�����s�����ƂŁA���f���̈�ʉ��\�͂����コ���A�ߊw�K��h�����Ƃ��ł���B
�摜�f�[�^�ɂ�����f�[�^�g���ł́A����AI��p���ĐV�����摜�����邱�Ƃ���ʓI�ł���B����ɂ́A�����̉摜����]��������A���]��������A�F����ύX�����肷��P���Ȏ�@����AGAN���g�p���đS���V�����摜�������蕡�G�Ȏ�@�܂ł��܂܂��B����ɂ��A�w�K�f�[�^�Z�b�g�̑��l���������A���f���������E�̂��܂��܂ȏɑΉ��ł���悤�ɂȂ�B
�e�L�X�g�f�[�^�ɂ����Ă��A����AI�𗘗p�����f�[�^�g�����s���Ă���B���R���ꏈ�����f���̃g���[�j���O�̂��߂ɁA�����̃e�L�X�g�f�[�^����V���ȕ��╶�͂����A�f�[�^�Z�b�g���g�[����B���̃v���Z�X�ɂ́A�P��̒u���A���̍č\���A�V�������̐����Ȃǂ��܂܂��B
�����f�[�^�̏ꍇ�A�f�[�^�g���͉����̃s�b�`�⑬�x��ύX������A�w�i�m�C�Y��lj����邱�Ƃɂ��s���邱�Ƃ������B����AI��p���邱�ƂŁA�����̕ϊ������������ꂽ���@�ōs���A��茻���I�ȃg���[�j���O�f�[�^�����邱�Ƃ��ł���B
�f�[�^�g���́A����ꂽ�ʂ̃g���[�j���O�f�[�^�������p�ł��Ȃ��ꍇ��A���f������茘�S�ɂ���K�v������ꍇ�ɓ��ɗL�p�ł���B����AI�����p���邱�ƂŁA�]���̎�@�ł͎����ł��Ȃ��������x���̃f�[�^�g�����\�ƂȂ�A�@�B�w�K���f���̐��\����ɍv�����Ă���B
3.4.4�@ ���p����ւ̓K�p
3.4.4.1�@ �}�[�P�e�B���O��L���ƊE�ł̊��p
�}�[�P�e�B���O��L���ƊE�ɂ����鐶��AI�̊��p�́A�ߔN�A�傫�Ȓ��ڂ��W�߂Ă���B����AI�́A�p�[�\�i���C�Y���ꂽ�L���R���e���c�̍쐬�A����҂̊S�������r�W���A���R���e���c�̐����A���ʓI�ȃ}�[�P�e�B���O�헪�̍���ȂǁA���܂��܂Ȍ`�Ŋ��p����Ă���B
�p�[�\�i���C�Y���ꂽ�L���R���e���c�̐����́A����AI�̏d�v�ȉ��p��ł���B����҂̉ߋ��̍w��������I�����C���ł̍s���p�^�[���͂��A���̏�����ɂ��ČX�̏���҂ɍ��킹���J�X�^�}�C�Y���ꂽ�L�����b�Z�[�W��摜������B����ɂ��A�L���̊֘A�������܂�A����҂̊S�������ʓI�Ɉ������邱�Ƃ��ł���B
�܂��A�r�W���A���R���e���c�̐����ɂ����Ă��A����AI�͑傫�Ȗ������ʂ����Ă���B�V���i�̃v�����[�V�����r�W���A����ASNS�p�̃N���G�C�e�B�u�ȉ摜�A�o�i�[�L���ȂǁA���͓I�Ŗڂ������r�W���A���R���e���c�̐������A����AI�ɂ��e�ՂɂȂ��Ă���B����GAN�̋Z�p�́A�ʐ^�̂悤�Ƀ��A���ȉ摜�����邱�Ƃ��\�ł���A�L���r�W���A���̕i�������コ����B
����ɁA����AI�̓}�[�P�e�B���O�헪�̍���ɂ����Ă����p����Ă���B����҂̍s����n�D�Ɋւ���f�[�^����C���T�C�g�𒊏o���A����Ɋ�Â��ă}�[�P�e�B���O�L�����y�[���̃R���Z�v�g��b�Z�[�W������B����ɂ��A���^�[�Q�b�g�ɍ��v�����A���ʓI�ȃ}�[�P�e�B���O�헪�̍��肪�\�ƂȂ�B
�}�[�P�e�B���O��L���ƊE�ɂ����鐶��AI�̊��p�́A��ƂɂƂ��ċ����͂����߂�d�v�ȗv�f�ƂȂ��Ă���B�������A�l�̃v���C�o�V�[�ی��ϗ��I�ȍL�����H�Ɋւ���ۑ�ɗ��ӂ��A�K�ȗ��p�����߂���B
3.4.4.2�@ �G���^�[�e�C�����g�ƊE�ł̗��p
�G���^�[�e�C�����g�ƊE�ɂ����鐶��AI�̗��p�́A�n�����ƋZ�p�̗Z���ɂ���ĐV���ȉ��l�ݏo���Ă���B�f��A���y�A�r�f�I�Q�[���A�����ăA�[�g�Ƃ���������ŁA����AI�̓R���e���c����̃v���Z�X��ϊv���A�ϋq�ɖ��̌��̃G���^�[�e�C�����g����Ă���B
�f��ƊE�ɂ����āA����AI�͓�����ʂ�w�i�̐����ɗ��p����邱�Ƃ������Ă���B���A����CG�L�����N�^�[�╗�i�����邱�ƂŁA����R�X�g�̍팸�ƂƂ��ɁA�f���\���̉\�����L���Ă���B�܂��A�r�{�̎���������A�����̉f���f�ނ���V���ȃV�[����n�o����������s���Ă���A�f�搧��̖����Ɋv�V�������炷�\�����߂Ă���B
���y����ł́A����AI��p�����y�Ȑ��삪���ڂ��W�߂Ă���BAI���w�K�����������̊y�Ȃ̃X�^�C������ɁA�I���W�i���̃����f�B��n�[���j�[������B����ɂ��A�A�[�e�B�X�g�͐V���ȃC���X�s���[�V�����邱�Ƃ��ł��A�n�슈���̕����L����B����ɁA����AI�ɂ�郉�C�u�p�t�H�[�}���X��A�C���^���N�e�B�u�ȉ��y�̌��̒��\�ƂȂ��Ă���B
�r�f�I�Q�[���ƊE�ɂ����ẮA����AI���Q�[�����̗v�f�������������邽�߂ɗp�����Ă���B�L�����N�^�[�A�A�C�e���A����ɂ̓Q�[���̃��x������܂ŁAAI���v���C���[�̍s����D�݂ɉ����ē��I�ɃR���e���c�����A���j�[�N�ȃQ�[���̌������B
�A�[�g�̗̈�ł́A����AI�����p�����V���ȃA�[�g��i�̑n�o���i��ł���BAI���w�K�������j�I�ȃA�[�g�X�^�C�������ɁA�Ǝ��̃r�W���A���A�[�g�����邱�ƂŁA�]���̃A�[�g����̘g������i�����ݏo����Ă���B
�G���^�[�e�C�����g�ƊE�ł̐���AI�̗��p�́A�ϋq�ɐV������������������ƂƂ��ɁA�N���G�C�^�[�̕\���̕����g���Ă���B�������AAI�ɂ��n�앨�̒��쌠��A�l�Ԃ̃N���G�C�^�[�̖����Ƃ������c�_�������N�����Ă���A�Z�p�̐i�W�ƂƂ��ɁA�����̉ۑ�ɑ����������͍�����Ă���B
3.4.4.3�@ �P�[�u���ƊE�ł̗��p��
�P�[�u��TV�ƊE�ɂ����鐶��AI�̗��p�́A�R���e���c�̐��E�V�X�e���̋����A�����҃f�[�^�̕��́A�p�[�\�i���C�Y���ꂽ�L���̒ȂǁA�����ʂɂ킽��B�����̋Z�p�́A�����̌��̌���ƋƊE�̃r�W�l�X���f���̊v�V��ڎw���Ă���B
���E�V�X�e���́A�P�[�u��TV�ƊE�ɂ����鐶��AI�̑�\�I�ȉ��p��ł���B����AI��p�������E�V�X�e���́A�����҂̉ߋ��̎���������D�݂͂��A����Ɋ�Â��ČX�̎����҂ɍœK�Ȕԑg��f��𐄑E����B����ɂ��A�����҂͎��g�̊S�ɍ������R���e���c��e�ՂɌ����邱�Ƃ��ł��A�����̌������シ��B
�����҃f�[�^�̕��͂ɂ����Ă��A����AI�͏d�v�Ȗ������ʂ����Ă���B�����҂̍s���p�^�[����n�D��[���������邱�ƂŁA�P�[�u��TV���Ǝ҂͂�薣�͓I�ȃR���e���c�����E���삷�邱�Ƃ��\�ƂȂ�B�܂��A�������̗\����ԑg�̍œK�ȕ����X�P�W���[���̍���ȂǁA�^�c�̌������ɂ��v�����Ă���B
�p�[�\�i���C�Y���ꂽ�L���̒́A�P�[�u��TV�ƊE�ɂ����鐶��AI�̉��p�̒��ł����ɒ��ڂ���Ă��镪��ł���B����AI�����p���邱�ƂŁA�����҈�l�ЂƂ�̋�����j�[�Y�ɍ��킹���L�������A���^�C���Ő������A�������邱�Ƃ��ł���B����ɂ��A�L���̌��ʂ����サ�A�L����ɂƂ��Ă����͓I�ȍL���v���b�g�t�H�[���ƂȂ�B
�P�[�u��TV�ƊE�ɂ����鐶��AI�̗��p�́A�����҂̃j�[�Y�ɉ����邾���łȂ��A�V���ȃr�W�l�X�`�����X��n�o����\���������Ă���B�������A�l�̃v���C�o�V�[�ی��f�[�^�̈��S���Ƃ������ۑ�ɑ���z�����K�v�ł���A�Z�p�̐i���ƂƂ��ɁA�����̖��ɑ��������̊J�����i�߂��Ă���B
3.4.5�@ ����AI�̎Љ�I�e��
����AI�̔��W�́A�Љ�S�̂ɑ���ȉe����^���Ă���B���̋Z�p�́A�N���G�C�e�B�u�Y�Ƃ̕ϊv�A�l�̃v���C�o�V�[�ƃZ�L�����e�B�̖��A�J���s��ւ̉e���ȂǁA�l�X�ȑ��ʂŎЉ�ɉe�����y�ڂ��Ă���B
�N���G�C�e�B�u�Y�Ƃɂ����鐶��AI�̗��p�́A�A�[�g�A���y�A���w�ȂǁA�l�Ԃ̑n�����̗̈�ɐV���ȉ\���������炵�Ă���BAI�ɂ���Đ������ꂽ��i�́A�]���̃N���G�C�e�B�u�ȃv���Z�X��⊮���A�V�����`���̃A�[�g��n�o����B�������A�����̋Z�p���l�Ԃ̃A�[�e�B�X�g�ɑ�����̂ƂȂ�̂��A���邢�͋���������̂ƂȂ�̂��ɂ��ẮA���������c�_���K�v�ł���B
�l�̃v���C�o�V�[�ƃZ�L�����e�B�ɑ��鐶��AI�̉e�����d�v�Ȍ��O�����ł���B���ɁA���A���ȉ摜��f���A����������\�͂́A�U���̊g�U�⍼�\�A�v���C�o�V�[�̐N�Q�Ƃ��������X�N�����߂�B����ɑΏ����邽�߂ɂ́A�Z�p�I�ȉ�����̊J���ƂƂ��ɁA�K�Ȗ@�I�g�g�݂̐��������߂���B
�J���s��ɂ����ẮA����AI�͈ꕔ�̐E���^�X�N�̎��������\�ɂ��A�J���̐�����ς���\��������B����ŁA�V���ȐE�Ƃ�X�L���̎��v�ݏo�����Ƃ��\�z�����B���̕ω��ɓK�����邽�߂ɂ́A�����P���̃V�X�e�����čl���A�����̘J���s��ɔ�����K�v������B
����AI�̎Љ�I�e���́A�Z�p�̗��p���@���̎d���ɑ傫���ˑ�����B���̂��߁A�Z�p�ҁA�������ĎҁA�Љ�S�̂����͂��A����AI�̃|�e���V�������ő���Ɋ��p���A���X�N���ŏ����ɗ}����o�����X�������邱�Ƃ��d�v�ł���B����AI�̔��W�́A�ϗ��I�ȃK�C�h���C���ƎЉ�I�ȍ��ӂɊ�Â��ׂ��ł���A���̉ߒ��œ������ƌ��������m�ۂ��邱�Ƃ����߂���B
3.4.6�@ ����AI�̌��������Ɩ���
3.4.6.1�@ ����AI�̌�������
����AI�̌����́A�Z�p�I�Ȑi���ƎЉ�I�Ȏ��v�̗����ɂ���ĉ�������Ă���B���̕���ɂ����錤�������́A�V�����A�[�L�e�N�`���̊J���A�w�K�v���Z�X�̍œK���A���p�͈͂̊g��Ƃ������������ɏW���B
�V�����A�[�L�e�N�`���̊J���ɂ����ẮA��荂�i���Ȑ������邽�߂̐V���ȃl�b�g���[�N�\�����T������Ă���B����ɂ́A�������f���̌����������コ����A���S���Y���̉��ǂ�A�قȂ�^�C�v�̐������f���̓����Ƃ������A�v���[�`���܂܂��B�܂��A�w�K�v���Z�X�̈��萫�����߂邽�߂̌������i�߂��Ă���A����GAN�ɂ����郂�[�h������ւ̑Ώ����d�v�ȉۑ�ƂȂ��Ă���B
����AI�̉��p�͈͂̊g��ɂ��ẮA�]���̗̈�ɉ����A��ÁA�����ƁA�s�s�v��Ƃ������V���ȕ���ւ̉��p���͍�����Ă���B�Ⴆ�A��É摜�̐����ɂ��f�f�x����A���i�v�̂��߂̐V�f�ނ̐����A�s�s�̃V�~�����[�V�����ɂ�鎝���\�ȓs�s�v��̍���Ȃǂ���������B
�����ɂ����鐶��AI�̌����́A�����̋Z�p�I�Ȑi���ɉ����A�ϗ��I�ȉۑ�ւ̑Ή����d�v�ȃe�[�}�ƂȂ�B�U���̊g�U��v���C�o�V�[�̐N�Q�Ƃ��������X�N�ւ̑�AAI�ɂ��n�앨�̒��쌠��I���W�i���e�B�̖��ւ̎��g�݂����߂��Ă���B�܂��AAI�Z�p�̖��剻�Ɍ������A�N�Z�X�̕�������A�Z�p�̓������Ɛ����ӔC�̊m�ۂ��A�����̌����ɂ����ďd�v�ȗv�f�ƂȂ�B
����AI�̖����́A�Z�p�I�Ȋv�V�ƂƂ��ɁA�Љ�I�ȐӔC�Ɨϗ��I�ȍl�������̂ƂȂ�B�����ҁA�J���ҁA�������ĎҁA�����ĎЉ�S�̂����͂��A����AI�������\�ŗϗ��I�ȕ��@�Ŕ��W������悤�Ɏ��g�ނ��Ƃ��d�v�ł���B
3.4.6.2�@ ����AI�̉\���ƌ��E
����AI�́A���̔��W�ɂ��A�N���G�C�e�B�u�ȍ�i�̐����A�f�[�^�g���A�p�[�\�i���C�Y���ꂽ�R���e���c�̒Ƃ����������̉\�����J���Ă���B�����̋Z�p�́A�G���^�[�e�C�����g�A�}�[�P�e�B���O�A��ÁA�Ȋw�����Ƃ��������L������Ŋv�V�������炵�A�l�Ԃ̑n�����Ɛ��Y����傫���g������B����AI�ɂ���Đ��ݏo���ꂽ�V�����A�C�f�A��R���e���c�́A�]���̕��@�ł͍l�����Ȃ������`�������������B
�������A����AI�̋Z�p�́A���̗��p���@��ړI�ɂ���ẮA�ϗ��I�Ȗ���Љ�I�Ȍ��O�������N�����\��������B�U���̐�����v���C�o�V�[�̐N�Q�A�m�I���Y���̖��́A���̋Z�p�̐ӔC����g�p�����߂鐺�����߂Ă���B�܂��AAI�ɂ�鎩�������i�ޒ��ŁA�J���s��ւ̉e����l�Ԃ̖����Ɋւ��鍪�{�I�Ȗ₢����N����Ă���B
����AI�̖����́A�����̋Z�p�̉\�����ő���Ɋ��p���A�����Ƀ��X�N���Ǘ����A�ϗ��I�Ȏw�j�ɉ������g�p���m�ۂ��邱�Ƃɂ������Ă���B���̂��߂ɂ́A�Z�p�ҁA�����ҁA�������ĎҁA����ɂ͈�ʂ̐l�X���܂߂��Љ�S�̂ł̑Θb�Ƌ��͂��s���ł���B
�ŏI�I�ɁA����AI�̉\���ƌ��E�́A�l�Ԃ������̋Z�p���ǂ̂悤�Ɏ���A�K�p���A�K�����邩�ɂ���Č`�����B����AI�̎����\�Ȕ��W�́A�Z�p�I�Ȑi�������łȂ��A�ϗ��I�A�Љ�I�ȓ��@�Ɋ�Â������I�ȃA�v���[�`��K�v�Ƃ���B����AI���l�ނɂƂ��Đ^�ɗL�v�ȃc�[���ƂȂ邽�߂ɂ́A���̉\����T�����A���E��F�����A���ɐ������邽�߂̓���͍�����K�v������B